
The new Bitmovin API delivers a comprehensive video infrastructure solution by integrating all aspects of the adaptive streaming workflow into one easy to use interface: Encoding, Player, Analytics, Storage and CDN
Video Infrastructure via an API
Product development at Bitmovin is driven by our customers’ business needs. By working closely with our users, we have built a deep understanding of how video infrastructure needs fit into a wide variety of different business models. This level of understanding helps us to prioritize features on our product roadmap and keep ourselves a step ahead of the game. Over the last few years, this feedback process has allowed us to create a vision for a complete video infrastructure, and with the release of the Bitmovin API this vision has become a reality. API Reference.
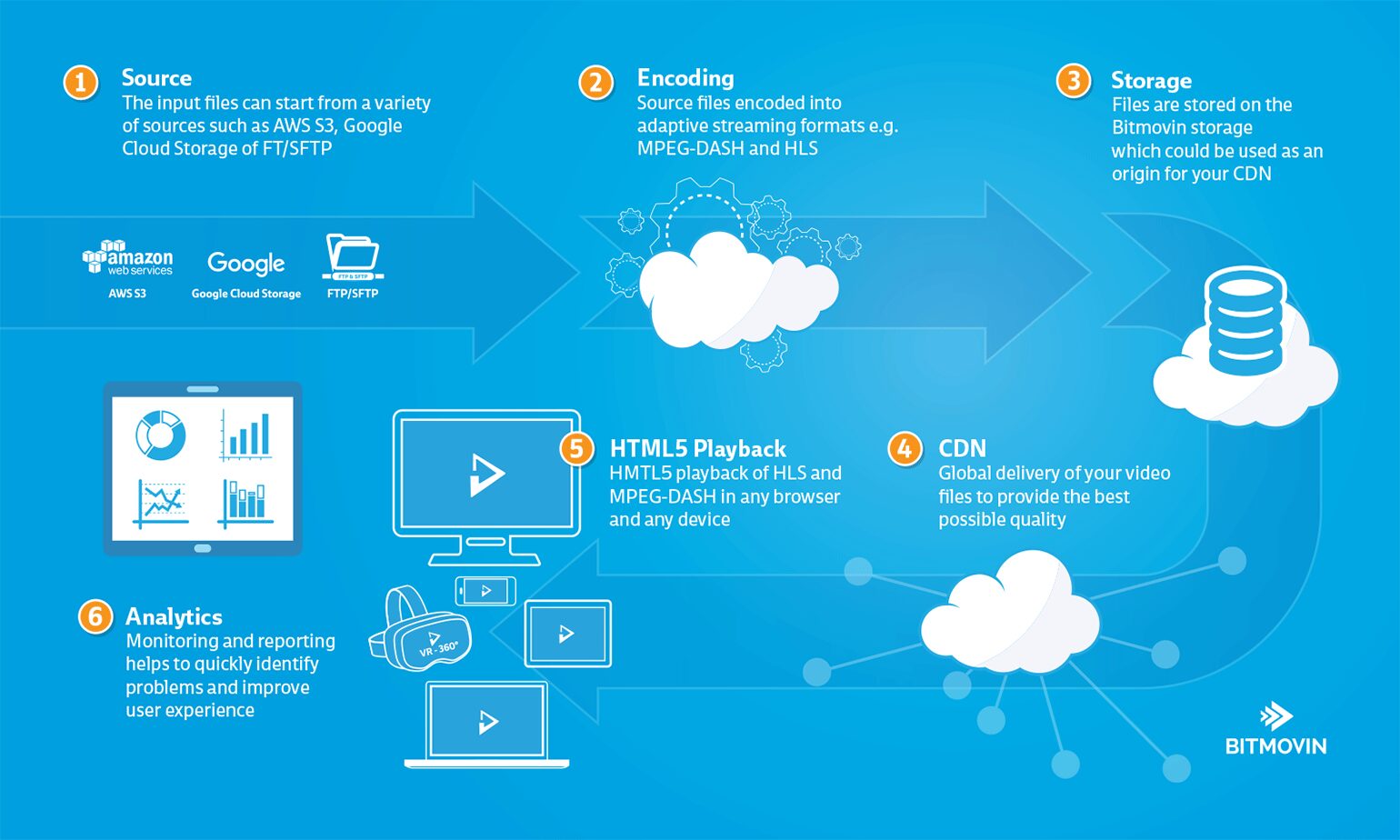
The typical workflow for media companies to prepare videos has usually 5 major components: Encoding, Storage, CDN, Player and Analytics, and the Bitmovin API provides all of these components now through one API. A video source file cannot be simply moved online as it usually has very high bitrates and is probably also encoded with a compression standard that is not supported on all the major devices. The internet, with its “best effort”, nature could transport such files but it could not guarantee that your users will not see frequent buffering and long startup delays and even playback failures with a video that is not prepared for internet delivery. This is where the Bitmovin API hooks into your workflow, you can now use our encoding API to prepare your files for internet delivery and store the encoded video on our storage. By doing so your files are already available through a CDN and you could get the CDN paths of your files from our API. By connecting our player then with the CDN path of the video you have created a Netflix like streaming system. To see what your users are experiencing you could connect our analytics to the player and monitor closely what’s happening with your streams. Its important to say that we provide all of these components through an API and they are also nicely integrated but you could also use each component individually, e.g., just the encoding or just the player, as everything is available through the API.
Flexibility
Flexibility was a very high priority during the design of the new API. We have seen through experience, that our customers have a wide variety of different use cases, each requiring unique configuration. With the old REST API this was often difficult to customize, because a lot of things were too rigidly defined. This prevented us from leveraging the full potential of our encoder, which is a very flexible multi-cloud enabled service. The new API resolves this, which on one hand has increased the complexity of the REST interface, but by building an abstraction layer into our API clients to provide simple workflow examples, we have maintained a high level of usability, while at the same time giving our solution architects tools that allow them to tailor the system easily for individual customers through these API clients.
Analytics
For quite some time we have had our own analytics in place to monitor our website and to identify potential errors. This system has helped us to catch errors early and in most cases before our customers. As many of you probably already know, our player is integrated with a lot of analytics solutions due to the fact that we have a very flexible player interface. We have integrated our own analytics through the same interface which means that it is not bound to a specific player and can be used with any player.
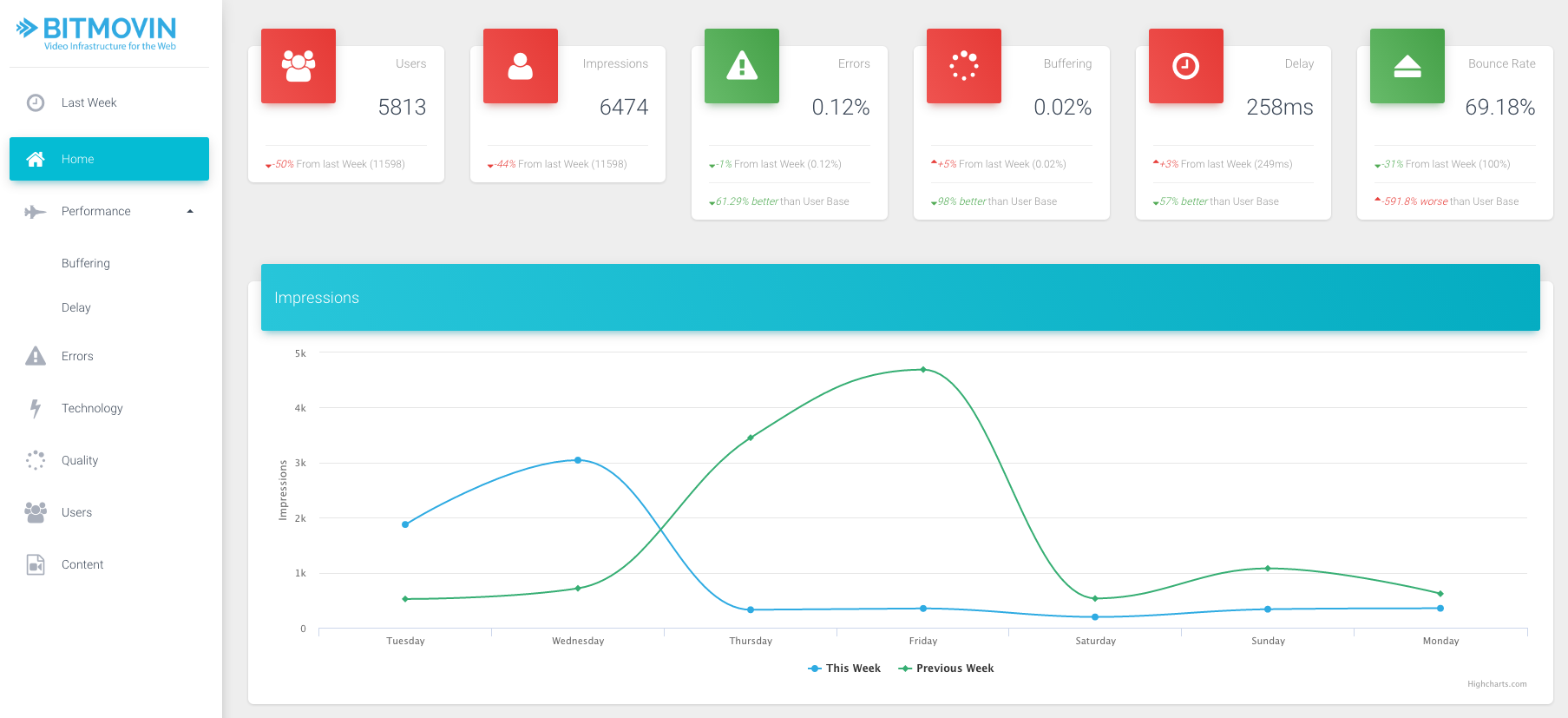
The analytics is realtime and, in line with our philosophy, available through the API. This means you can easily integrate it into your backend and create metrics and graphs as you see fit. We will provide examples and a reporting dashboard as an open source component, where you will simply need to insert your API key to get started.
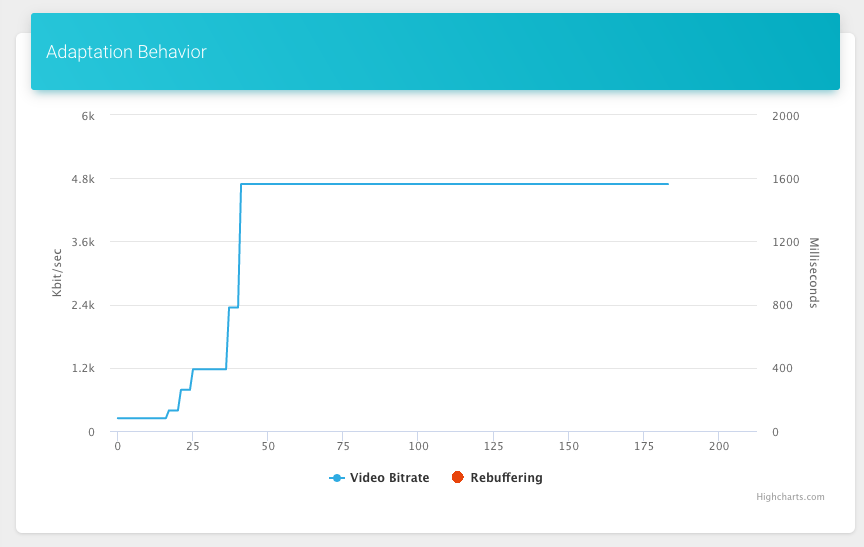
You could analyze the adaptation behavior of your video player and setup experiments to compare different adaptation logics. We also use this to debug sessions that had frequent buffering or other problems and it really helps to get behind the actual problem.
Storage and CDN
We have also integrated many CDNs (Akamai, Level3, Fastly, Highwinds, CloudFront, Limelight, CloudFlare, etc.) and Storages (AWS S3, GCS, Azure Blob, FTP, SFTP, Aspera, etc.) over the last few years, but we have also seen that many customers where struggling with the integration phase. Based on customer requests we have tightened up these integrations so you can use these storage options directly through our API. Of course you still have the option to use your own storage, but for users looking to bootstrap quickly it’s now much easier.
Design & Architecture
The Bitmovin API is based on microservices with high availability in multiple clouds, e.g., AWS, Google, etc. As a company, we have gained considerable knowledge in this area, as many services in the old encoding API are also based on microservices. The difference here is that this time we have built the entire system as a microservice architecture with a single API gateway that is hosted in a high availability configuration.
Each microservice is encapsulated in a Docker container and we maintain 4 separate branches of each service; internal, canary, production and enterprise. We can route every request based on certain characteristics into one of these 4 branches. A typical roll-out of a feature looks as follows: We test it on our internal branch, and if all system tests run through we deploy a new version into our canary branch. A certain percentage of our production traffic will then be routed into this canary branch (this could be configured on a per service basis). If everything works well, after one week, we create a release version of this service and deploy it into production. This version will be explicitly tested against our enterprise customer use cases and if all tests run through, we deploy it as a canary for our enterprise branch which means we route a certain percentage of our enterprise requests onto this branch. If everything works well, after a week, we deploy the service into production for the enterprise branch.
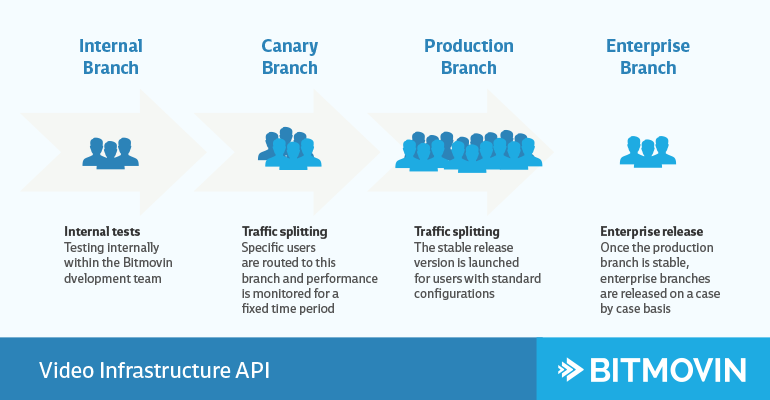
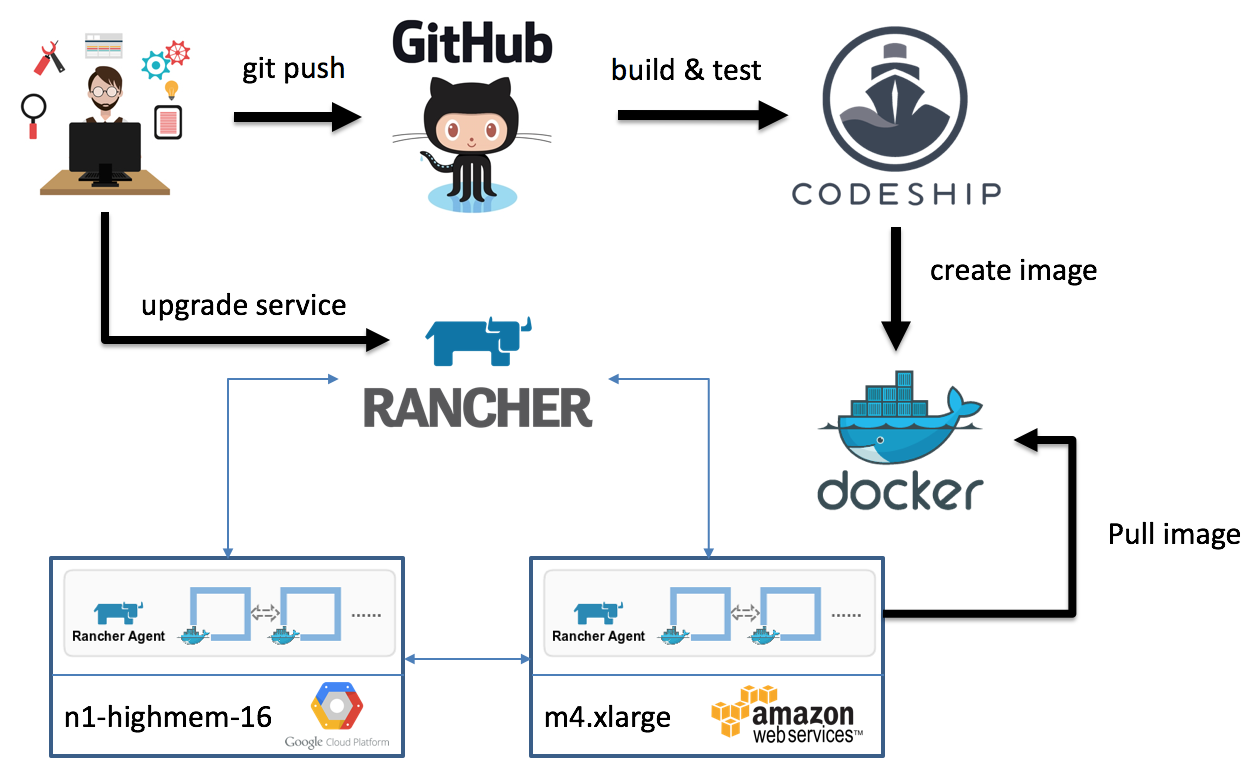
A typical deployment workflow of a feature is as follows:
- A developer pushes code to a microservice git repository hosted on GitHub.
- Internally, we work with git flow and trigger builds when somebody opens a pull request.
- This pull request will be reviewed by at least another developer and needs to pass all of our unit and integration tests before we create a first SNAPSHOT for our system tests.
- The builds will be automatically triggered and executed on CodeShip where all unit and integration tests will be performed.
- If the feature passes all tests, an image will be created and pushed to DockerHub.
Our management layer consists currently of about 1000 containers (this includes all 4 branches) that are all hosted in an High Availability (HA) configuration, which means that each service has at least two containers that are on different hosts and different availability zones or regions. For the orchestration of these containers we use Rancher, which provides us with an overlay network and service discovery for all of these containers. If the image is available on DockerHub, the developer could test the feature on our internal branch. This means he/she will create a new service and connect it to the internal branch in Rancher. Once online, we can execute our system tests on our internal branch to see if everything is working as expected.
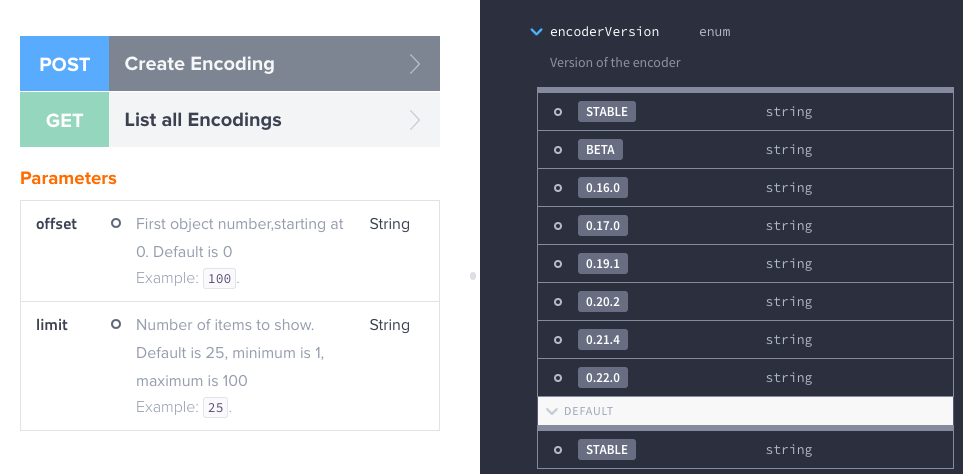
Encoder upgrades are now also more transparent for our customers. For each encoding you can specify the encoder version that you want to use, or use one of our tags like STABLE or BETA that always contain the latest stable version or the latest beta version. This allows you to decide when you want to upgrade to a new encoder version and provides you full control and transparency into our development.
The API Specification
The REST API specification describes all resources of our new API and should only be used to develop API clients. These clients are advanced wrappers on top of our REST API itself and have been made in order to help you integrate the service into your apps. Everything that can be done using the REST API can be done using those clients. Using our API clients is recommended to get the best from our service. They are all open-source and available on Github. You should only use our REST API to develop new API clients. We are currently in the process of writing API clients for the new API and we have already some available:
During the next few months we will add more API clients prioritized by customer requests and we will constantly update these clients when we add features to our API. On our list are currently Go, Java, C#, Node, Ruby, JavaScript, CMD Client and Scala.
Every response of our API is contained in an envelope. This means that each response has a predictable set of attributes with which you can expect to interact. The envelope format is described in the API specification in the section Response Format. All error codes of the API are described in the section Error Codes. We will provide further details for this errors and dedicated support pages but you should also get resolution suggestions directly from the API with the error code.
An example of a successful response from the API looks as follows:
{
"requestId": "6d84e126-d10c-4e52-bbfb-bd4c92bc8333",
"status": "SUCCESS",
"data": {
"result": {
"name": "Production-ID-678",
"description": "Project ID: 567",
"id": "cb90b80c-8867-4e3b-8479-174aa2843f62",
"bucketName": "video-bucket",
"cloudRegion": "EU_WEST_1",
"createdAt": "2016-06-25T20:09:23.69Z",
"modifiedAt": "2016-06-25T20:09:23.69Z"
},
"messages": [
{
"date": "2016-06-25T20:09:23.69Z",
"id": "cb90b80c-8867-4e3b-8479-174aa2843f62",
"type": "INFO",
"text": "Input created successfully"
}
]
}
}
Each response contains a unique requestId that identifies your request. It can be used to trace the path of your request and for debugging in error cases. Internally this is a correlation ID that will be forwarded by every microservice and is also present in our logs. This helps us to identify problems quickly and accurate. The status could only have two values SUCCESS and ERROR. The data field then contains the actual response from the service.
In this case the user created an input on AWS S3. The result field contains the service specific result and additional messages. Messages are used in successful and error responses to communicate details about the workflow. The Message object contains information of a single message. The type of the message could be either, INFO, ERROR, WARNING, DEBUG or TRACE. Typically you will see INFO messages and exceptional some WARNING and ERROR messages. DEBUG and TRACE will only be shown, if enabled for your account, or on beta features.
Error responses have the same base structure as successful responses but the status indicates that the response is an error. In that case the requestId is more important and can be handed over directly to our support, which could then provide additional details.
{
"requestId": "6d84e126-d10c-4e52-bbfb-bd4c92bc8333",
"status": "ERROR",
"data": {
"code": 1000,
"message": "One or more required fields are not valid or not present",
"developerMessage": "Exception while parsing input fields",
"links": [
{
"href": "https://bitmovin.com/docs",
"title": "Tutorial: DASH and HLS Adaptive Streaming with AWS S3 and CloudFront"
}
],
"details": [
{
"date": "2016-06-25T20:09:23.69Z",
"id": "cb90b80c-8867-4e3b-8479-174aa2843f62",
"type": "ERROR",
"text": "Exception while parsing field 'accessKey': field is empty",
"field": "accessKey",
"links": [
{
"href": "https://docs.aws.amazon.com/general/latest/gr/managing-aws-access-keys.html",
"title": "Managing Access Keys for your AWS Account"
}
]
}
]
}
}
The data field of the error response contains a specified error code that you can lookup to get further information. Beside that we include a message that could be used in your app or presented to a user to indicate this error. The developerMessage is something that you will typically log on your side and targets the developer of the application. It provides more details and should help to fix the error. Additionally, we include links that help you to resolve the error. In this example the AccessKey for the AWS S3 input was missing and the link targets a tutorial how you typically set this up. The service could also include messages with further details as in that case a parsing exception occurred on the accessKey field. The API responds with that error and also includes a link how you can get your access and secret keys from AWS.
Feature Overview
The Bitmovin API enables a lot of encoding new use cases for our customers and we want to highlight some here:
- Hollywood-/Netflix-grade DRM: Widevine, PlayReady, Marlin and PrimeTime DRM with MPEG-CENC
- Fairplay DRM with HLS
- DASH Clear Key encryption
- HLS Sample AES and AES-128 encryption
- Advanced Encoding Options for H264/AVC
- Advanced Encoding Options for H265/HEVC
- 4K and 60FPS Livestreaming
- Livestreaming with DRM
- Livestreaming with direct output to S3 and GCS
- Multi-Cloud: Configure cloud and region for every encoding (AWS, Google), for both, Live and OnDemand
- Add filters to VoD and live encoding, e.g., watermark
- Multiple outputs per encoding
- Direct MP4, MPEG2-TS, etc. output
- Multi tenant support
- Closed Captions/Subtitles: Add multiple sidecar files to encoding, e.g., WebVTT, SRT, TTML (SMPTE-TT, EBU-TT or DFXP), etc.
- Support for 608/708 closed captions
- Extract and embed closed captions and subtitles
- Add custom metadata to resources
- Multiple different input files for one encoding (multi-audio or multi-view use cases)
- Allow separate audio and video input files for encodings
- Direct pass through for AWS S3 and GCS without storing files
- Optimized turnaround times for short clips
- Fragmented MP4 with HLS (MPEG-CENC)
- Create thumbnails and sprites directly with the encoding
Complete new products like Analytics, Storage and CDN are now also part of the API. Our Analytics has its roots in our development process, where it is used internally for health monitoring of our releases and error reporting. You never know if everything is still working as expected after a Chrome or Firefox update and so we build the original Analytics system to monitor our own website which helps us to identify problems early on, even before our customers see them. We provide a lot of statistics for developers, which help you to debug specific events and work out what is happening. For example, a video is not playing as it should on a specific Chrome version or you are seeing frequent rebuffering in US with a specific ISP.
Same for startup delay or errors that occur or quality that is probably worse under certain circumstances. You could identify problems earlier by comparing your current performance in terms of buffering, startup delay, quality, etc. to the day before or to the last week/month and so on. These metrics can also be compared to our user base so that you see where you stay compared to industry average, e.g., is your buffering average higher than the average buffering of our whole user base.
What will happen next?
We will continue to extend this API with new features and use cases and will also implement more API clients in different languages. We want to provide the complete video infrastructure as a service for our customers making it as easy as possible for you to setup flexible video workflows. Beside that, our development roadmap is also highly influenced by our customers, so feel free to reach out to us if a critical feature for your use case is missing – we will make it possible 😉
Video technology guides and articles
- Back to Basics: Guide to the HTML5 Video Tag
- What is a VoD Platform? A comprehensive guide to Video on Demand (VOD)
- Video Technology [2022]: Top 5 video technology trends
- HEVC vs VP9: Modern codecs comparison
- What is the AV1 Codec?
- Video Compression: Encoding Definition and Adaptive Bitrate
- What is adaptive bitrate streaming
- MP4 vs MKV: Battle of the Video Formats
- AVOD vs SVOD; the “fall” of SVOD and Rise of AVOD & TVOD (Video Tech Trends)
- MPEG-DASH (Dynamic Adaptive Streaming over HTTP)
- Container Formats: The 4 most common container formats and why they matter to you.
- Quality of Experience (QoE) in Video Technology [2022 Guide]


