

*This post was originally published in June 2023. It was updated in May 2024 with more recent research publications and updates.*
TL;DR
- AI is transforming video encoding and streaming optimization by enabling smarter compression decisions that improve visual quality while reducing bitrate and infrastructure costs
- Machine learning models enhance perceptual quality optimization, allowing encoding decisions to better reflect how humans actually perceive video rather than relying solely on traditional metrics
- Content-aware encoding powered by AI dynamically adapts parameters based on scene complexity, motion, and visual characteristics to maximize compression efficiency
- AI-driven quality metrics outperform legacy measurement approaches, improving the alignment between objective scores and real viewer experience
- Ongoing AI video research is focused on long-term streaming efficiency, including reducing bandwidth consumption, lowering carbon footprint, and enabling more scalable, sustainable video delivery
This post will summarize the current state of Artificial Intelligence (AI) applications for video in 2024, including recent progress and announcements. We’ll also take a closer look at AI video research and collaboration between Bitmovin and the ATHENA laboratory that has the potential to deliver huge leaps in quality improvements and bring an end to playback stalls and buffering. This includes ATHENA’s FaRes-ML, which was recently granted a US Patent. Keep reading to learn more!
Table of Contents
AI for video at NAB 2024
At NAB 2024, the AI hype train continued gaining momentum and we saw more practical applications of AI for video than ever before. We saw various uses of AI-powered encoding optimization, Super Resolution upscaling, automatic subtitling and translations, and generative AI video descriptions and summarizations. Bitmovin also presented some new AI-powered solutions, including our Analytics Session Interpreter, which won a Best of Show award from TV Technology. It uses machine learning and large language models to generate a summary, analysis and recommendations for every viewer session. The early feedback has been positive and we’ll continue to refine and add more capabilities that will help companies better understand and improve their viewers’ experience.

Other AI highlights from NAB included Jan Ozer’s “Beyond the Hype: A Critical look at AI in Video Streaming” presentation, NETINT and Ampere’s live subtitling demo using OpenAI Whisper, and Microsoft and Mediakind sharing AI applications for media and entertainment workflows. You can find more detail about these sessions and other notable AI solutions from the exhibition floor in this post.
FaRes-ML granted US Patent
For a few years before this recent wave of interest, Bitmovin and our ATHENA project colleagues have been researching the practical applications of AI for video streaming services. It’s something we’re exploring from several angles, from boosting visual quality and upscaling older content to more intelligent video processing for adaptive bitrate (ABR) switching. One of the projects that was first published in 2021 (and covered below in this post) is Fast Multi-Resolution and Multi-Rate Encoding for HTTP Adaptive Streaming Using Machine Learning (FaRes-ML). We’re happy to share that FaRes-ML was recently granted a US Patent! Congrats to the authors, Christian Timmerer, Hadi Amirpour, Ekrem Çetinkaya and the late Prof. Mohammad Ghanbari, who sadly passed away earlier this year.
Recent Bitmovin and ATHENA AI Research
In this section, I’ll give a short summary of projects that were shared and published since the original publication of this blog, and link to details for anyone interested in learning more.
Generative AI for Adaptive Video Streaming
Presented at the 2024 ACM Multimedia Systems Conference, this research proposal outlines the opportunities at the intersection of advanced AI algorithms and digital entertainment for elevating quality, increasing user interactivity and improving the overall streaming experience. Research topics that will be investigated include AI generated recommendations for user engagement and AI techniques for reducing video data transmission. You can learn more here.
DeepVCA: Deep Video Complexity Analyzer
The ATHENA lab developed and released the open-source Video Complexity Analyzer (VCA) to extract and predict video complexity faster than existing method’s like ITU-T’s Spatial Information (SI) and Temporal Information (TI). DeepVCA extends VCA using deep neural networks to accurately predict video encoding parameters, like bitrate, and the encoding time of video sequences. The spatial complexity of the current frame and previous frame are used to rapidly predict the temporal complexity of a sequence, and the results show significant improvements over unsupervised methods. You can learn more and access the source code and dataset here.
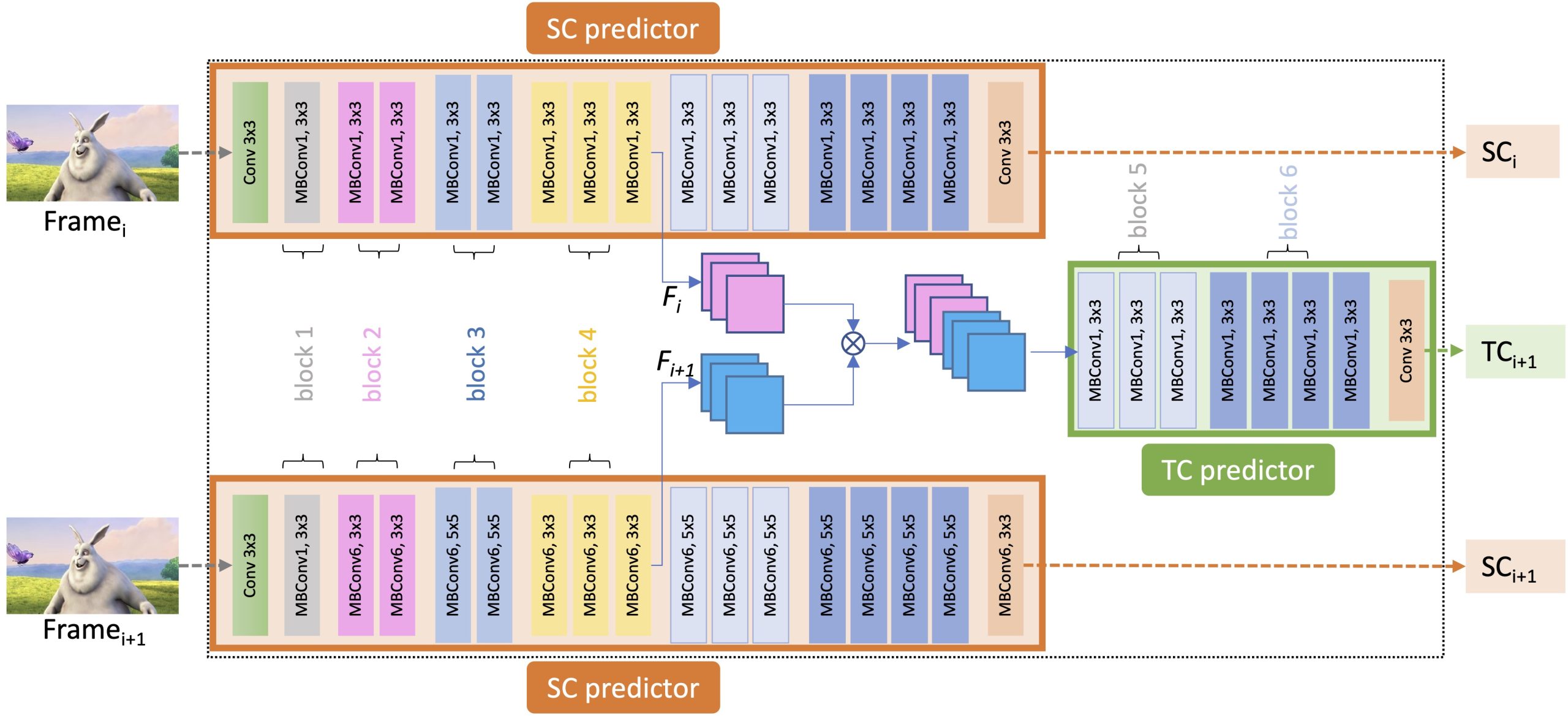
DIGITWISE: Digital Twin-based Modeling of Adaptive Video Streaming Engagement
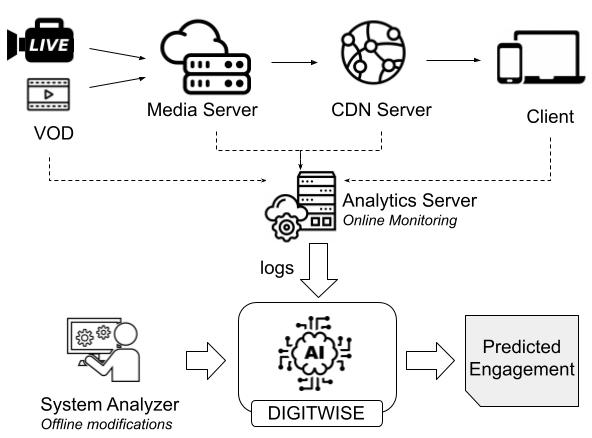
DIGITWISE leverages the concept of a digital twin, a digital replica of an actual viewer, to model user engagement based on past viewing sessions. The digital twin receives input about streaming events and utilizes supervised machine learning to predict user engagement for a given session. The system model consists of a data processing pipeline, machine learning models acting as digital twins, and a unified model to predict engagement (XGBoost). The DIGITWISE system architecture demonstrates the importance of personal user sensitivities, reducing user engagement prediction error by up to 5.8% compared to non-user-aware models. It can also be used to optimize content provisioning and delivery by identifying the features that maximize engagement, providing an average engagement increase of up to 8.6 %.You can learn more here.
Previous Bitmovin and ATHENA AI Research
Better quality with neural network-driven Super Resolution upscaling
The first group of ATHENA publications we’re looking at all involve the use of neural networks to drive visual quality improvements using Super Resolution upscaling techniques.
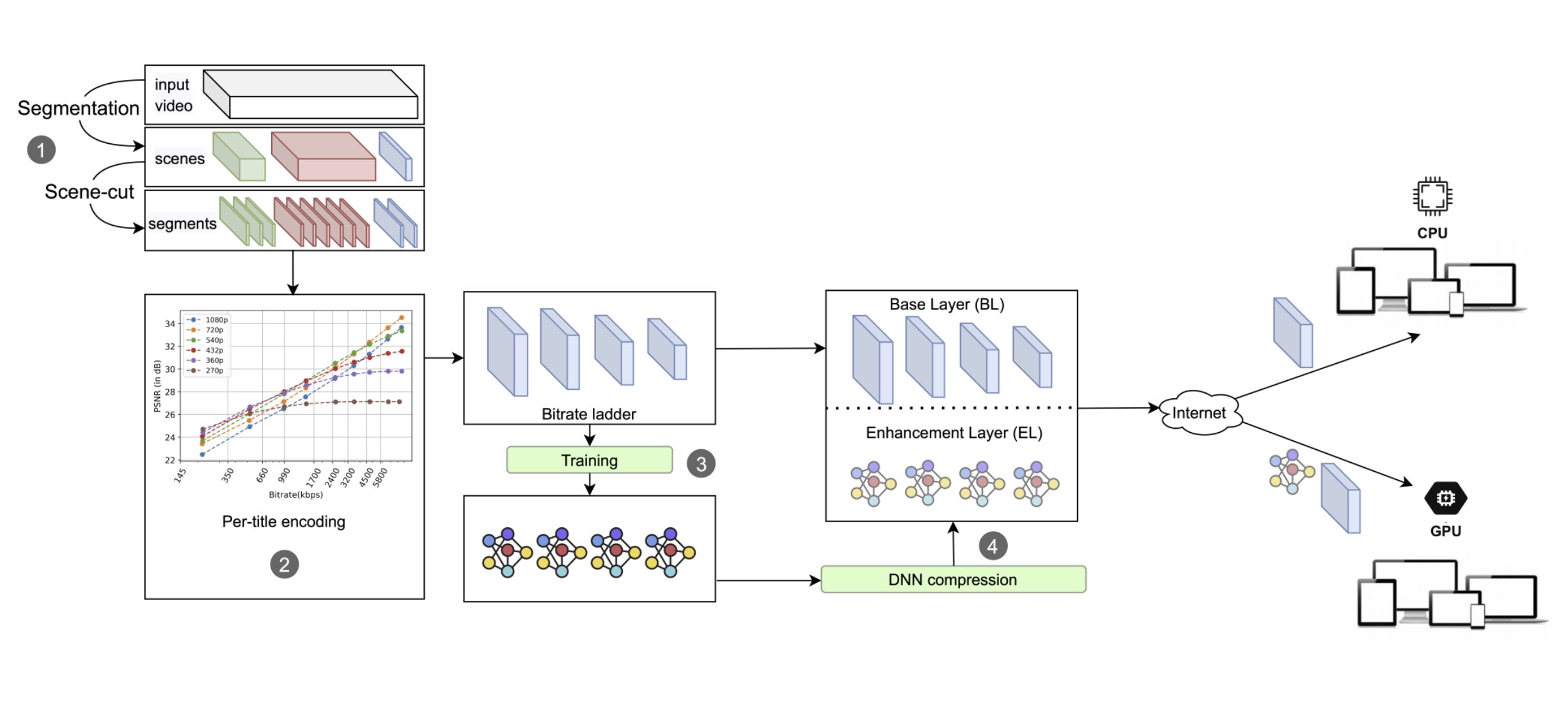
DeepStream: Video streaming enhancements using compressed deep neural networks
Deep learning-based approaches keep getting better at enhancing and compressing video, but the quality of experience (QoE) improvements they offer are usually only available to devices with GPUs. This paper introduces DeepStream, a scalable, content-aware per-title encoding approach to support both CPU-only and GPU-available end-users. To support backward compatibility, DeepStream constructs a bitrate ladder based on any existing per-title encoding approach, with an enhancement layer for GPU-available devices. The added layer contains lightweight video super-resolution deep neural networks (DNNs) for each bitrate-resolution pair of the bitrate ladder. For GPU-available end-users, this means ~35% bitrate savings while maintaining equivalent PSNR and VMAF quality scores, while CPU-only users receive the video as usual. You can learn more here.
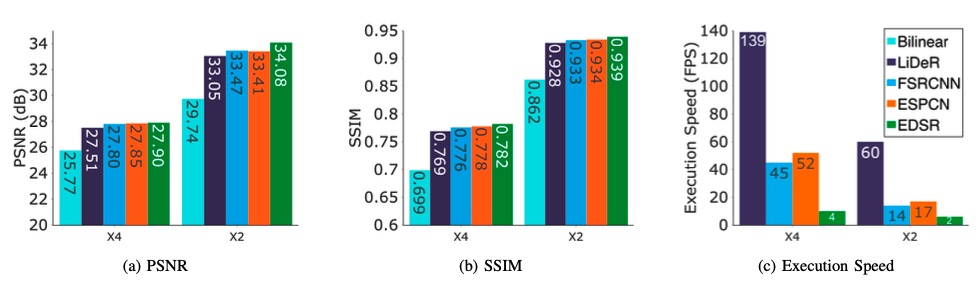
LiDeR: Lightweight video Super Resolution for mobile devices
Although DNN-based Super Resolution methods like DeepStream show huge improvements over traditional methods, their computational complexity makes it hard to use them on devices with limited power, like smartphones. Recent improvements in mobile hardware, especially GPUs, made it possible to use DNN-based techniques, but existing DNN-based Super Resolution solutions are still too complex. This paper proposes LiDeR, a lightweight video Super Resolution network specifically tailored toward mobile devices. Experimental results show that LiDeR can achieve competitive Super Resolution performance with state-of-the-art networks while improving the execution speed significantly. You can learn more here or watch the video presentation from an IEEE workshop.
Super Resolution-based ABR for mobile devices
This paper introduces another new lightweight Super Resolution network, SR-ABR Net, that can be deployed on mobile devices to upgrade low-resolution/low-quality videos while running in real-time. It also introduces a novel ABR algorithm, WISH-SR, that leverages Super Resolution networks at the client to improve the video quality depending on the client’s context. By taking into account device properties, video characteristics, and user preferences, it can significantly boost the visual quality of the delivered content while reducing both bandwidth consumption and the number of stalling events. You can learn more here or watch the video presentation from Mile High Video.
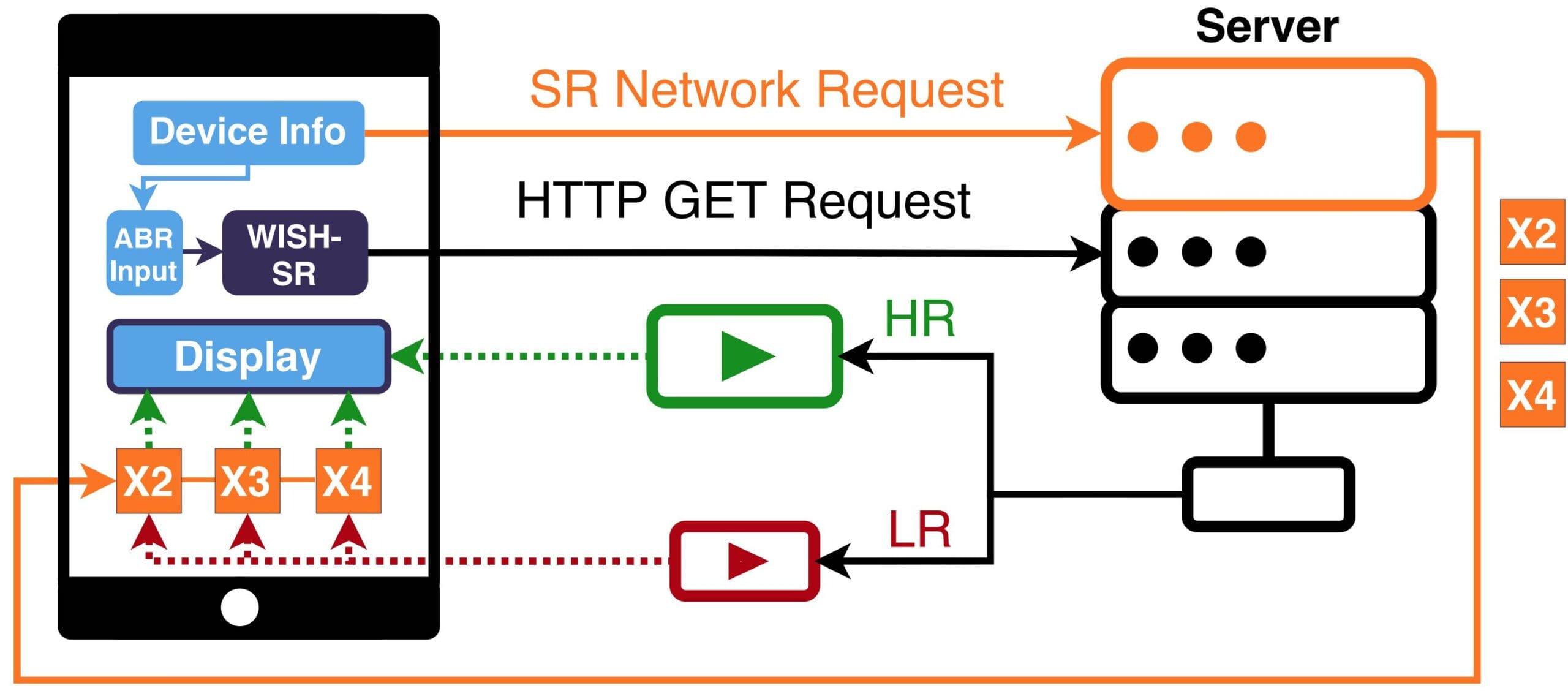
Less buffering and higher QoE with applied machine learning
The next group of research papers involve applying machine learning at different stages of the video workflow to improve QoE for the end user.
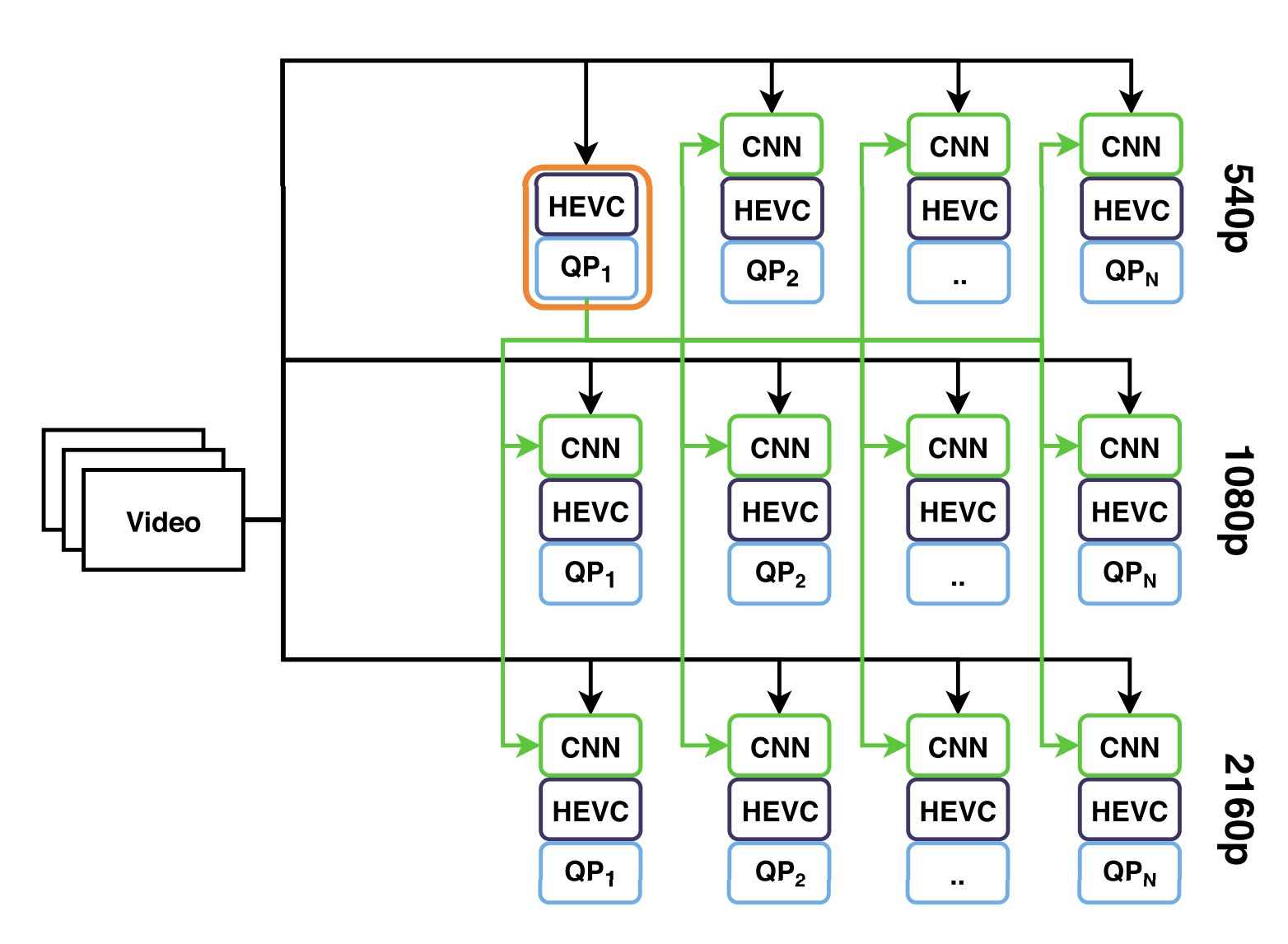
FaRes-ML: Fast multi-resolution, multi-rate encoding
Fast multi-rate encoding approaches aim to address the challenge of encoding multiple representations from a single video by re-using information from already encoded representations. In this paper, a convolutional neural network is used to speed up both multi-rate and multi-resolution encoding for ABR streaming. Experimental results show that the proposed method for multi-rate encoding can reduce the overall encoding time by 15.08% and parallel encoding time by 41.26%. Simultaneously, the proposed method for multi-resolution encoding can reduce the encoding time by 46.27% for the overall encoding and 27.71% for the parallel encoding on average. You can learn more here.
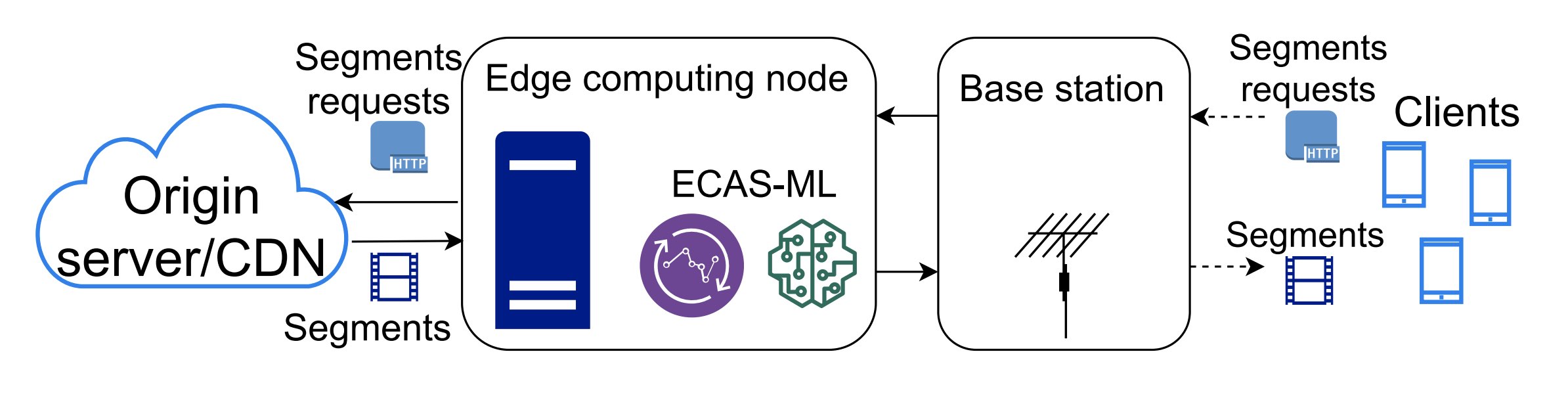
ECAS-ML: Edge assisted adaptive bitrate switching
As video streaming traffic in mobile networks increases, utilizing edge computing support is a key way to improve the content delivery process. At an edge node, we can deploy ABR algorithms with a better understanding of network behavior and access to radio and player metrics. This project introduces ECAS-ML, Edge Assisted Adaptation Scheme for HTTP Adaptive Streaming with Machine Learning. It uses machine learning techniques to analyze radio throughput traces and balance the tradeoffs between bitrate, segment switches and stalls to deliver a higher QoE, outperforming other client-based and edge-based ABR algorithms. You can learn more here.
Challenges ahead
The road from research to practical implementation is not always quick or direct or even possible in some cases, but fortunately that’s an area where Bitmovin and ATHENA have been working together closely for several years now. Going back to our initial implementation of HEVC encoding in the cloud, we’ve had success using small trials and experiments with Bitmovin’s clients and partners to provide real-world feedback for the ATHENA team, informing the next round of research and experimentation toward creating viable, game-changing solutions. This innovation-to-product cycle is already in progress for the research mentioned above, with promising early quality and efficiency improvements.
Many of the advancements we’re seeing in AI are the result of aggregating lots and lots of processing power, which in turn means lots of energy use. Even with processors becoming more energy efficient, the sheer volume involved in large-scale AI applications means energy consumption can be a concern, especially with increasing focus on sustainability and energy efficiency. From that perspective, for some use cases (like Super Resolution) it will be worth considering the tradeoffs between doing server-side upscaling during the encoding process and client-side upscaling, where every viewing device will consume more power.
Learn more
Want to learn more about Bitmovin’s AI video research and development? Check out the links below.
Analytics Session Interpreter webinar
AI-powered video Super Resolution and Remastering
Super Resolution with Machine Learning webinar
AI Video Glossary
Machine Learning – Machine learning is a subfield of artificial intelligence that deals with developing algorithms and models capable of learning and making predictions or decisions based on data. It involves training these algorithms on large datasets to recognize patterns and extract valuable insights. Machine learning has diverse applications, such as image and speech recognition, natural language processing, and predictive analytics.
Neural Networks – Neural networks are sophisticated algorithms designed to replicate the behavior of the human brain. They are composed of layers of artificial neurons that analyze and process data. In the context of video streaming, neural networks can be leveraged to optimize video quality, enhance compression techniques, and improve video annotation and content recommendation systems, resulting in a more immersive and personalized streaming experience for users.
Super Resolution – Super Resolution upscaling is an advanced technique used to enhance the quality and resolution of images or videos. It involves using complex algorithms and computations to analyze the available data and generate additional details. By doing this, the image or video appears sharper, clearer, and more detailed, creating a better viewing experience, especially on 4K and larger displays.
Graphics Processing Unit (GPU) – A GPU is a specialized hardware component that focuses on handling and accelerating graphics-related computations. Unlike the central processing unit (CPU), which handles general-purpose tasks, the GPU is specifically designed for parallel processing and rendering complex graphics, such as images and videos. GPUs are widely used in various industries, including gaming, visual effects, scientific research, and artificial intelligence, due to their immense computational power.
Video Understanding – Video understanding is the ability to analyze and comprehend the information present in a video. It involves breaking down the visual content, movements, and actions within the video to make sense of what is happening.
FAQs
What is AI video research in the context of streaming?
AI video research applies machine learning models to optimize video encoding, compression efficiency, and perceptual quality in streaming workflows.
How does AI improve video encoding?
AI enhances encoding by analyzing video content characteristics and dynamically adjusting encoding parameters to maintain visual quality while minimizing bitrate.
What is content-aware encoding?
Content-aware encoding uses AI models to evaluate scene complexity, motion, texture, and other characteristics to optimize compression decisions on a per-scene or per-segment basis.
Does AI replace traditional codecs like AV1, HEVC, or AVC?
No. AI enhances existing codec implementations by optimizing encoding decisions; it does not replace standardized codecs.
How does AI reduce streaming bandwidth costs?
By improving compression efficiency, AI enables equivalent or better visual quality at lower bitrates, which reduces CDN traffic and storage requirements.


