


TL;DR
- AI-driven sign language avatars enable scalable accessibility by translating spoken audio into sign language overlays
- Modern AI models are orchestrated in a pipeline that converts speech to text, text to semantic meaning, and meaning to sign language motion
- Sign language video streams can be delivered as separate renditions or overlays, integrating cleanly into existing adaptive streaming workflows
- Cloud-based processing and real-time inference make sign language accessibility viable for both VOD and live streaming use cases
- This approach significantly reduces cost, latency, and operational complexity compared to traditional sign language video production, while improving inclusivity and regulatory readiness
Table of Contents
Streaming has the power to connect diverse audiences, but making video content accessible for all remains a challenge. Accessibility must be a priority, especially for deaf and hard-of-hearing viewers who face unique barriers. While helpful for some, traditional subtitles (both audio and visual) lack the richness and expressiveness of sign language, limiting access to key information and emotional nuances. To bridge this gap in the market, our team at Bitmovin explored leveraging AI technologies to introduce sign language avatars into video streams. This innovative approach converts text representations of American Sign Language (ASL) poses into client-side avatars, creating a more inclusive solution without requiring additional video channels or picture-in-picture features.
In this blog, we’ll share how we approached this challenge, detailing our initial assumptions, workflow design, key components of the solution, and insights gained along the way. Starting with subtitle text tracks as input data to validate the feasibility of this groundbreaking method, paving the way to make streaming more accessible for all.
Solution Overview
We implemented the project through a multi-step pipeline that integrates AI and machine learning-driven natural language processing (NLP) with 3D animation technologies. In general, it can be broken down into two important main components, a server-side component and a client-side one.
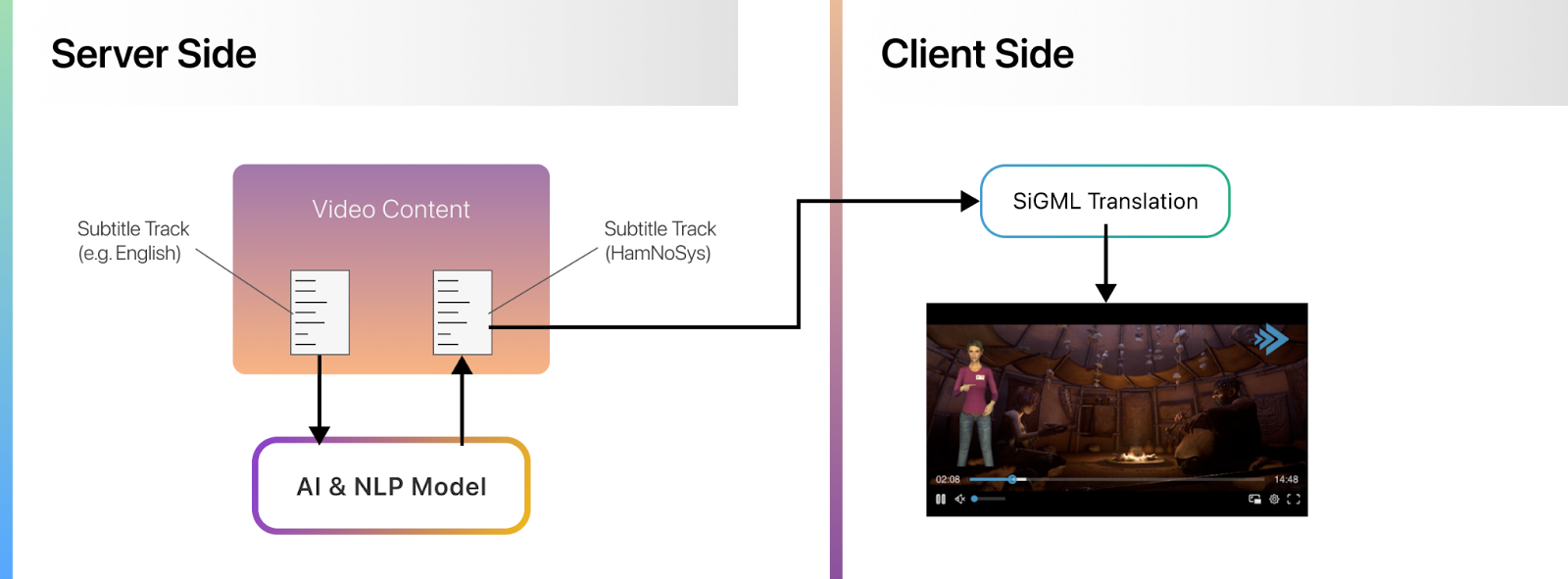
Server-side component: For each video asset, the existing subtitle text tracks are used to generate an additional “subtitle track” containing a representation in HamNoSys (Hamburg Notation System for Sign Language), a standardized transcription system designed to represent sign language gestures in written form (more on that later). This text-based sign-track is stored and delivered as part of the video asset, just like any other subtitle track. Generating the sign-track can be done on-demand (whenever requested by the client video player) or as part of the existing encoding and packaging workflow. There are no limitations in regards to which streaming technology can be used here, it works perfectly for DASH and HLS.
Client-side component: Whenever a video containing a sign-track is played back and the sign-track is activated in the video player, a customizable 3D avatar is initialized and rendered alongside the video. The HamNoSys representation from the sign-track, as well as the contained timing information, is used to generate ad-hoc SiGML (Signing Gesture Markup Language) descriptions of the single gestures and poses, which in turn are fed into the rendering and animation engine of the 3D avatar.
This diagram illustrates the whole end-to-end pipeline, from sign-track generation on the server-side, to animating a customizable 3D avatar that is integrated into the video player on the client-side.
How we implemented it
1. Server-side processing: Text to HamNoSys
HamNoSys (Hamburg Notation System) is a standardized phonetic transcription system designed to represent sign language gestures in written form. It was developed to provide a consistent and systematic way to document and analyze the visual-spatial elements of sign languages, focusing on the specific features of hand shapes, locations, movements, and facial expressions that makeup signs.
As mentioned above, the input used for the translation to HamNoSys in this scenario is the existing subtitle text tracks from the video asset. In our first prototype, we are using Gloss as an intermediate representation, which can be seen as a simplified form of sign language grammar, transcribing a one-to-one correspondence with individual signs. This Gloss representation allowed us to re-use some existing tooling [1],[2], and is later translated into HamNoSys based on a mapping from publicly available databases.
Roughly, the whole translation workflow looks like this:
- Tokenization of input text
- Removal and filtering of stop words and punctuation
- Lemmatization to derive base word forms
- Reordering of words to align with sign language grammar rules of American Sign Language (ASL)
- Generation of final Gloss representation
- Translation of Gloss representation to HamNoSys
2. Client-side processing and animation
Building upon the CWA Signing Avatar project [3], we integrated the 3D avatar into our suite of world-class video players. The avatar expects SiGML as input; an XML-based language specifically designed to represent sign language gestures for digital applications, such as 3D avatars or sign language recognition systems.
For the sign-tracks, we chose to use HamNoSys instead of SiGML as it is a much more compact representation in producing SiGML on the server-side, and delivering it to the video player would have increased the file size of the sign-track by 10x. Also, the conversion from HamNoSys to SiGML is relatively low complexity and is therefore suitable to be done on the client-side, which we did by following the approach as outlined in this publication [4].
A challenge we discovered with the client-side integration was matching the timing of the animations with the speed of the audio, so we had to implement a synchronization mechanism to automatically speed up or slow down the animation based on the timing information included in the sign-track.
Advantages
Our solution for generating and integrating sign language into video content offers several key advantages that make it a compelling approach to enhancing accessibility:
Compatibility
By representing sign language as a dedicated subtitle track, our solution seamlessly integrates with existing video players and streaming technologies. This means that video players don’t need any special modifications to support sign language or can choose to simply ignore it like a subtitle track of an unknown language. Therefore, whether you’re using DASH, HLS, or any other streaming protocol, our sign language tracks can be delivered alongside the video content using standard streaming formats and workflows. This universal compatibility ensures that sign language can be easily added to video content across various platforms and devices.
Flexible Avatar Integration
Our approach allows for flexible and simple integration of 3D avatars into video players to visually represent sign language. As the avatar’s animation is driven by the timing and content information embedded in the sign language subtitle track, any video player that exposes subtitle cues can be readily extended to support the avatar overlay. Additionally, the appearance, behavior and even position of the avatar can be customized to match the preferences of individual users or to align with specific branding guidelines.
No Additional Video Content
Another key benefit of representing sign language as a subtitle track and flexible avatar is removing the reliance on creating separate video content for sign language often displayed as a Picture-in-Picture experience. While seemingly more straightforward, the PiP approach suffers from some drawbacks:
- Not all video players and streaming platforms support PiP functionality, restricting the reach and accessibility of sign language content.
- Many Android TVs for example can only decode one video at a time
- The PiP window can obscure parts of the main video, potentially distracting viewers and hindering their ability to fully engage with the content.
- Delivering an additional video track for sign language significantly increases bandwidth consumption, potentially leading to buffering issues and slower loading times, particularly for users with limited internet connectivity.
- The additional video track download and decoding increases battery usage
- Significantly higher storage requirement on the server as two videos have to be stored instead of one, leading to higher cost.
- Users often have limited control over the position and size of the PiP window, which can further impact the viewing experience, especially for users with visual impairments.
- Subtitle tracks are quicker and easier to update than video, which requires a longer workflow of regenerating and re-encoding, especially if it’s a human signer being recorded.
Challenges and Shortcomings
While our solution demonstrates the potential of AI-driven sign language generation for video content, it’s important to acknowledge the current limitations and areas for future improvement:
- Gloss doesn’t capture the full grammatical complexity of ASL. It’s more of a literal, word-for-sign translation. For example, in a glossed sentence, signs might be represented as English words, with no regard for ASL’s unique syntax
- HamNoSys is designed for representing and analyzing sign language grammar as text but does not provide adequate information for translation back into sign language. Sign language transition and superposition are not supported by HamNosys.
- Timing of the animated gestures
- Representing and animating facial expressions are a crucial part of sign language.
- Limited by subtitles as sign languages convey more emotion and context. Further solutions to sign language generation need to use more data sources (audio, video, subtitle, etc.) to include more accurate contextual information in the signing.
Where to go from here
Some ideas on what steps we can look into next to progress this project to help create a more valuable and useful experience for the deaf community:
- Explore alternative intermediate representations beyond HamNoSys and Gloss, to capture more nuanced and natural signing grammar.
- Utilizing stochastic models, such as Hidden Markov Models (HMMs) or Recurrent Neural Networks (RNNs), could allow the system to learn and predict the probabilities of different sign sequences, leading to more natural and contextually appropriate sign language generation.
- Multi-modal data processing for a fusion of audio, subtitle, and visual cues to create a more holistic understanding of the content, and therefore more accurate sign language.
- Generate sign language poses on the server-side and use the sign-tracks to simply contain the avatar pose instructions, removing the client-side SiGML processing and making the avatar sign-language agnostic.
- Explore more sophisticated models that can accurately capture and reproduce the complex movements of facial muscles involved in sign language expressions, including emotion recognition analysis from the source video to help synthesize facial expressions.
- Continue to partner with and gain feedback from more members of the deaf community and university researchers in sign language linguistics.
Conclusion
As we’ve explored in this blog post, AI-powered sign language generation holds immense potential to bridge the communication gap for deaf and hard-of-hearing individuals. By seamlessly integrating sign language into video content, we can create a more inclusive and accessible digital landscape where everyone can fully participate and enjoy the richness of visual storytelling.
Our approach, leveraging AI and NLP technologies, offers a compelling approach that is both compatible with existing video player infrastructure and flexible enough to adapt to future advancements. This is a hard problem to automate and while the challenges remain in areas such as linguistic representation, facial expression modeling and synchronization, ongoing research and collaboration with academic institutions are paving the way for significant improvements.
We envision a future where sign language is readily available alongside spoken dialogue in all forms of video content, from educational materials and entertainment to news broadcasts and social media. This will not only empower deaf and hard-of-hearing communities but also enrich the viewing experience for everyone by providing a deeper understanding and appreciation of diverse communication styles. By embracing innovation and fostering collaboration, we can collectively strive toward a future where video content is truly accessible and inclusive for all.
—
Stay up to date on how we’re leveraging AI at Bitmovin to innovate streaming workflows by joining the Bitmovin AI Community today!
References
[1] https://nlp.stanford.edu/software/lex-parser.shtml
[2] https://stanfordnlp.github.io/stanza
[3] https://vhg.cmp.uea.ac.uk/tech/jas/std/
[4] https://aclanthology.org/2020.lrec-1.739.pdf
FAQs
How does AI generate sign language from video audio?
The system typically combines automatic speech recognition (ASR), natural language processing (NLP), and sign language generation models to convert spoken language into sign language gestures.
Is AI sign language translation real-time or offline?
Both models are supported. Real-time processing enables live streams, while offline processing is used for video-on-demand workflows.
How is AI sign language delivered to the viewer?
Sign language can be delivered as a separate video stream, an overlay, or an alternative rendition within adaptive bitrate streaming formats.
Does AI sign language work with existing streaming standards like DASH or HLS?
Yes. AI-generated sign language is compatible with modern adaptive streaming architectures and standard delivery protocols.
How accurate are AI-generated sign language avatars?
Accuracy depends on the maturity of the AI models and training data. While not yet equivalent to human interpreters in all contexts, quality continues to improve rapidly.
What are the main technical components involved in AI sign language?
Key components include speech-to-text engines, language understanding models, sign language generation models, and a rendering layer for video output.
Is AI sign language cost-effective for large content libraries?
Yes. Automation dramatically reduces the marginal cost of accessibility for large-scale VOD catalogs and frequent live events.


