

Super-Resolution: What’s the buzz and why does it matter?
Super-resolution has been gaining steam recently. Many companies, secretly and not-so-secretly, have been incorporating this technology into their workflow. Most notably:
- Samsung has started advertising this feature in their latest flagship phone camera’s – boasting 64MP cameras that use super-resolution for zooming in during the photo capture process
- Other upstart companies are exploiting super-resolution to “upsample” videos and bring back videos to life that were captured centuries ago.
- Image editing applications like Pixelmator pro are using this feature to provide an enhanced end-user experience.
Although the idea of super-resolution has been around for quite some time, it’s recent resurgence in media applications has been driven primarily by advances in Machine Learning (ML). In the age of 4K and 8K quality content – super-resolution is an increasingly relevant topic in the field of video and will only continue to grow.
So in this series, I will try to shed some light on :
- What is ML-based super-resolution?
- Why is super-resolution so enticing for the video companies? And what are its advantages?
- Why does super-resolution matter for you, and how can you incorporate it within your own video workflows?
What is Video Sampling
Before jumping directly into the deep end, let’s get some basics in order. Starting from simple digital signals and building all the way up to ML-based super-resolution.
Digital Signals
Videos are sequences of images. And an image essentially is nothing but a two-dimensional digital signal. And processing this digital signal is of utmost importance for most electronic devices. Especially, if you concern yourself with video transmission and picture quality.
Resampling digital signals
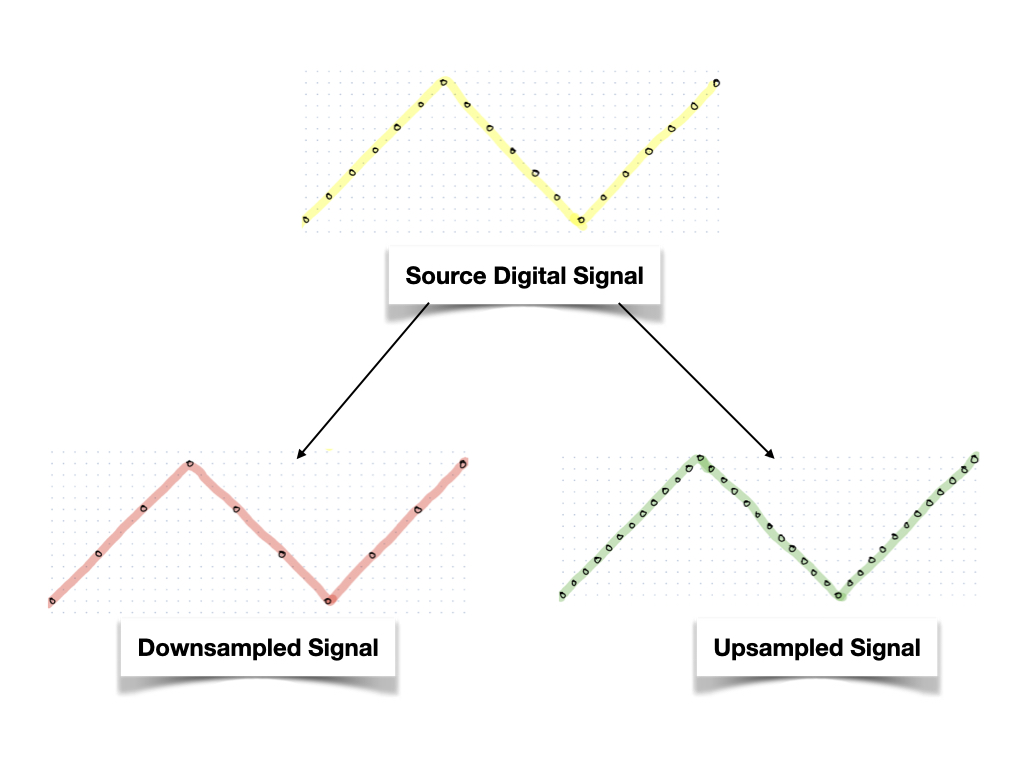
Next, within a digital signal, post-processing is almost always required. One of the commonly applied post-processing steps is known as “resampling”. Resampling is changing the sampling rate of a digital signal. Or, in simple words, for a given time duration, we change the number of samples in the signal.
Within resampling, one could do two things. You could either:
Upsample
- To predict new information from the pre-existing information. Or in other words, you are increasing the number of samples in a given time. This is also known as interpolation sometimes.
Downsample
- To throw away existing information. Or in other words, you are decreasing the number of samples in a given time.
This idea is depicted in the following figure.
Resampling video
As explained earlier, video is nothing but a digital signal. And there is usually a need to sample this digital video signal (we will look at some practical examples below). Since super-resolution concerns itself only with video upsampling, the rest of the series will focus only on the video upsampling.
To reiterate, video upsampling is the process of predicting new video samples from pre-existing video samples.
Why Upsample?
Is there a need to upsample to videos? And more importantly, is there a business opportunity behind it?
Let’s look at some real-world use cases and the types of upsampling to explain its relevance towards modern-day media. There are two primary types of upsampling: Temporal and Spatial.

Temporal Upsampling
Temporal upsampling is to predict video information across time-dimension using pre-existing information. This is best displayed in the iconic film series, The Matrix; if you are old enough to remember the famous “Neo vs Agent Smith Fight” scene from the movie Matrix Reloaded you’ll know that this movie was shot in the year 2003. One of the fascinating aspects of the scene is that it alternates between 12000 frames per second (fps) (this is super-slow-motion) and 24 fps (normal-speed).
In the year 2003, filmmakers certainly did not have a camera that can shoot at 12000 fps. Cameras were only capable of shooting a maximum of 24 fps. So, the filmmakers had to do sophisticated interpolation to obtain the 12000 frames (per second) from the pre-existing 24 frames (per second). In other words, they predict digital samples across temporal dimensions.
Spatial Upsampling
On the other side, Spatial upsampling is the process of predicting information across the spatial dimension.

Imagine, now that you have an old catalog of classic movies that you want to enjoy on your new crisp 4K-TV. The classic movies were (expectedly) not shot in 4K resolution. So to convert low-resolution movies, say 360p to a higher 4K resolution would require spatial upsampling. You need spatial upsampling to go from 172800 pixels (360p) to 8294400 (4k) pixels. In other words, you predict digital information across spatial dimensions.
So, to answer the original question at the beginning.
- YES! there is a need to upsample videos.
- And, an even emphatic, YES! there is a huge business opportunity behind it.
Super-resolution primarily deals with spatial upsampling. Hence, we will restrict our focus for the remainder of the series only on spatial upsampling.
Spatial Upsampling in Video
You might already be familiar with some of the other well-known methods to spatially upsample videos; the most common ones being bilinear, bicubic, or lanczos. Essentially, the idea behind all of these methods is that they use a single predefined mathematical function to predict new digital video samples from the pre-existing ones.

The emphasis on “single predefined mathematical function” is important. This is a key point, and that we will revisit that later.
Now, in a similar vein, super-resolution is a class of techniques to perform upsampling of videos. There are several flavors of super-resolution. But they are based on the same core principle: they use information from several images (typically neighboring images in video) to spatially upsample a single low-resolution image to a high-resolution image.
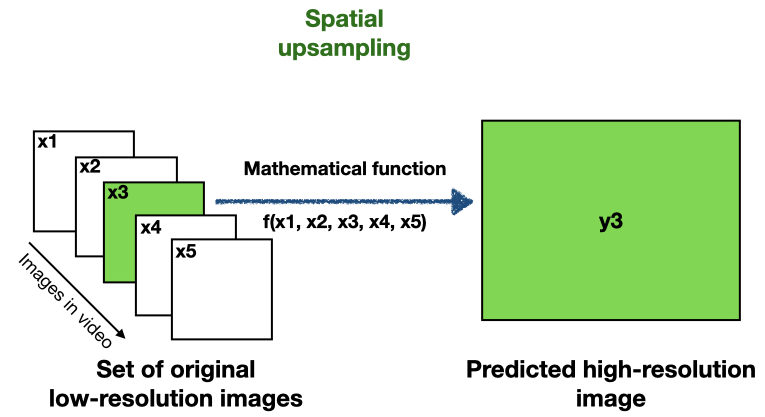
Note that in contrast to the spatial upsampling methods mentioned before, super-resolution uses information from several neighboring images to interpolate a single low-resolution image. And because it combines multiple information sources, it is able to better interpolate the image than the methods mentioned above. And this is one of the reasons why super-resolution is already popularly applied by companies such as AMD and NVIDIA, to render video games at high resolutions (4k).
Going forward, we will focus on super-resolution applications in a typical video workflow. We will especially focus on ML-based super-resolution. And discover the superior benefits it offers over conventional methods in video workflows.
Why ML-based super-resolution and why is it so much better? We will answer this in the next series of posts. So stay tuned!
Conclusion
The following figure summarizes everything we learned in this blog post.
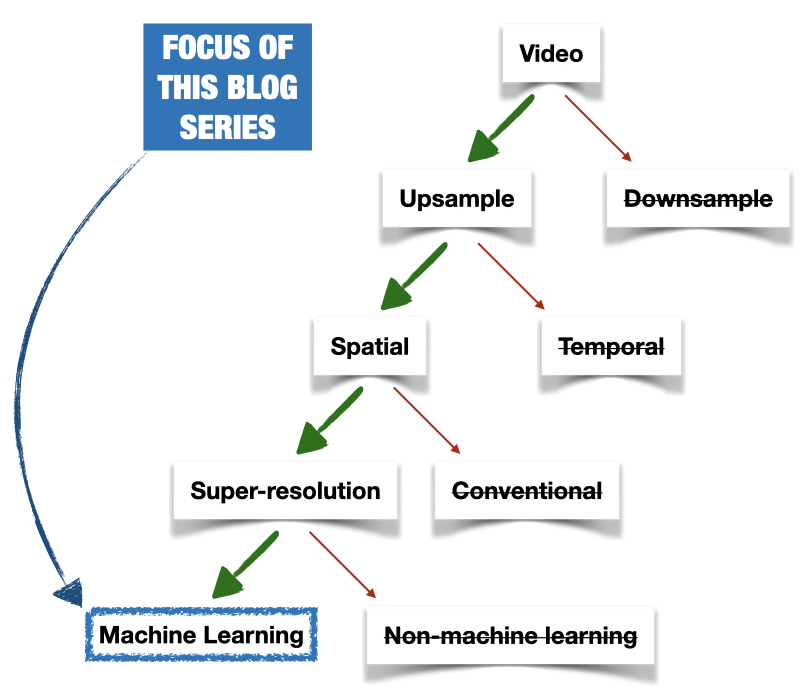
There is a big business opportunity behind upsampling videos, especially spatial upsampling of videos. Super-resolution is a class of techniques to spatially upsample video. Broadly, super-resolution can be categorized into two categories: machine learning-based and non-machine learning-based. This blog series will focus on machine learning-based super-resolution and the superior benefits it offers in video workflows.
Did you enjoy this post? Want to learn more?
Check out part two of the Super-Resolution series: Super-Resolution with Machine Learning P2
Check out part three: Practical Super-Resolution Deployments and Ensuing Results


