
Super-Resolution: Why is it good and how can you incorporate it?

Introduction
Welcome to Part 2 of Bitmovin’s Video Tech Deep Dive series: Super-Resolution with Machine learning. Before you get started, I highly recommend that you read Part 1. But if you would rather prefer to directly jump into it, here is a quick summary:
- Spatially upsampling videos is a huge business opportunity.
- Super-Resolution is a class of techniques to spatially upsample videos.
- Super-Resolution can be categorized into two categories: machine-learning based and non-machine-learning based.
- This blog series will focus on machine learning-based super-resolution.
In this post, we will examine:
- What factors lead to the current popularity of machine learning-based super-resolution?
- Why is it better than the other conventional methods?
- And, finally, how you can incorporate it into your video workflow and what benefits will super-resolution yield?
The Holy Trinity: Super-Resolution, Machine learning, and Video upscaling
Super-resolution, Machine learning (ML), and Video Upscaling are a match made in heaven. The three factors coming together is the reason behind the current popularity in Machine-learning based super-resolution applications. In this section, we will see why.
Super-Resolution and its beginnings
The concept of super-resolution has existed since the 1980s. The basic idea behind super-resolution was (and continues to be) to intelligently combine non-redundant information from multiple related low-resolution images to generate a single high-resolution image.
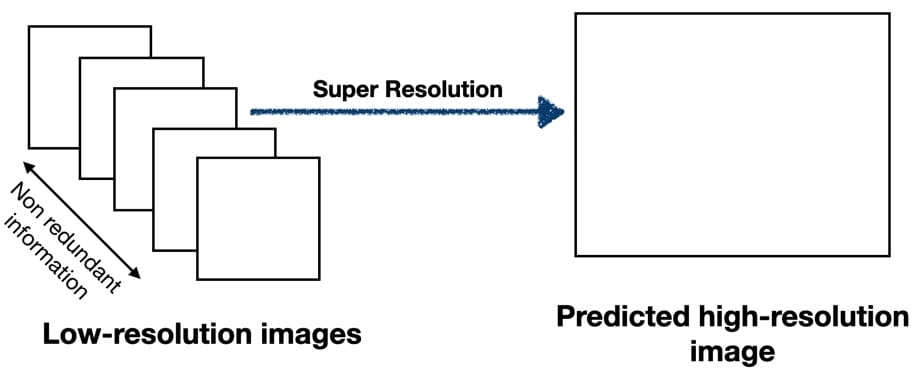
Some classic early applications were finding license plate information from several low-resolution images.

When super-resolution started out, the “intelligence” was, roughly speaking, a set of predefined and complex mathematical formulas (Image observation model, Interpolation-restoration, among others). The “intelligence” at the beginning had nothing to do with ML.
But the recent wave of interest in super-resolution has been primarily driven by ML.
Machine learning’s resurgence
So, why ML and what changed now?
ML, in essence, is about learning the “intelligence” for a well-defined problem. With the right architecture and enough data, ML can be significantly more “intelligent” than a human-defined solution (at least in that narrow domain). We saw this demonstrated stunningly in the case of AlphaZero (for chess) and AlphaGo (for the board game Go).
Super-resolution is a well-defined problem, and one could reasonably argue that ML would be a natural fit to solve this problem. With that motivation, early theoretical solutions were already proposed in the literature.
But, the exorbitant computational power and fundamental unresolved complexities kept the practical applications of ML-based super-resolution at bay.
However, in the last few years, there were two major developments:
- The enormous increase in the computational power density, especially the purpose-built Graphical Processing Units (GPUs), and also their affordability.
- Fundamental advances in ML, especially Convolutional Neural Network (CNNs), and their ease of use.
These developments have led to a resurgence and come back for ML-based super-resolution methods.
It should be mentioned that ML-based super-resolution is a versatile hammer that can be used to drive many nails. It has wide applications, ranging from medical imaging, remote sensing, astronomical observations, among others. But as mentioned in Part 1 of this series, we will focus on how the ML super-resolution hammer can nail the problem of video upscaling.
The convergence of the three factors
The last missing puzzle piece in this arc of the story is Video upscaling.

When you think about it, video upscaling is almost a perfect “nail” for the ML-based super-resolution “hammer”.
Video provides the core features needed for the ML-based Super-Resolution. Namely:
- It has related non-redundancy built-in: Every single frame in a video almost always has a set of closely “related” frames. And if there is enough motion of an object in the frame, all those related frames should provide non-redundant information about objects in the frame.
- The vast amount of available data: We have no shortage of video. These vast data could be used to train the ML network and let the network learn the best to upscale intelligence.
The convergence of these three factors is why we are witnessing a huge uptick in the research in this area, and also the first practical applications in the field of ML Super-Resolution powered Video upscaling.
Why is it better than traditional methods?
I provided a historical timeline and the factors that lead to ML Super-Resolution powered Video upscaling. But, it might still not be clear on why it is superior to other traditional methods (bilinear, bicubic, Lanczos, among others). In this section, I will provide a simplified explanation to provide an intuitive understanding.
The superior performance simply boils down to the fact that the algorithm understands the nature of the content it is upsampling. And how it tunes itself to upsample that content in the best way possible. This is in contrast to the traditional methods where there is no “tuning”. In traditional methods, the same formula is applied without any consideration of the nature of the content.
One could say that:
ML-based super-resolution is to upsampling, what Per-Title is to encoding.
In Per-Title, we use different encoding recipes for the different pieces of content. In a similar way, ML-based super-resolution uses different upsampling recipes for different pieces of content.
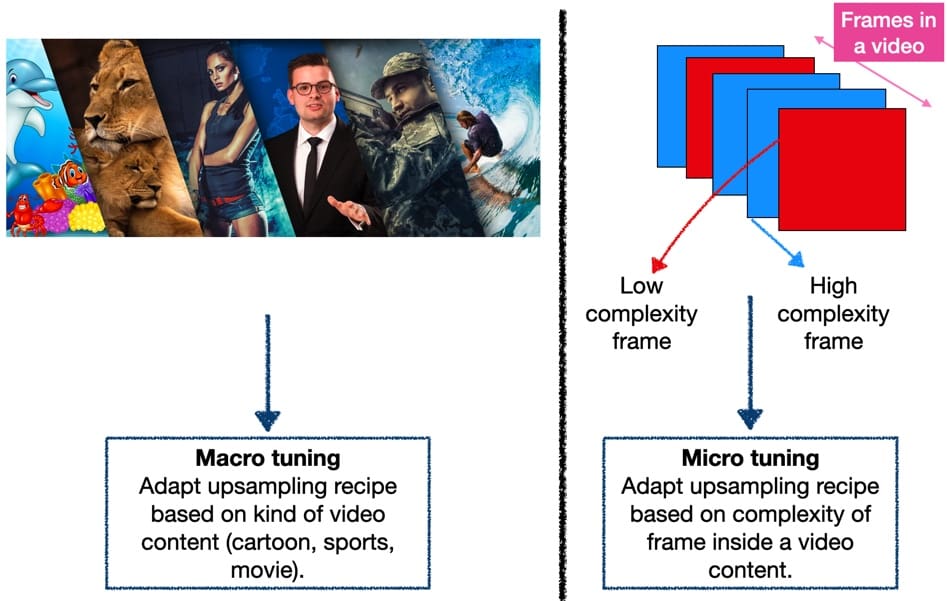
The recipes can adapt itself on both at the:
- Macro-level: Use different upsampling recipes for different types of content (anime, movie, sports, among others)
- Micro-level: Use different upsampling recipes for different types of frames within the same content (high complexity frame, low complexity frame).
Why do you need Super-Resolution with Machine-Learning?
Hopefully, by now, you are already excited about the possibilities of this idea. In this section, I would like to provide some suggestions on how you can incorporate this idea into your own video workflows and the potential benefits you might expect from it.
Quality
Broadly speaking, a video processing workflow typically has three steps involved:
- Pre-processing (decoding, upsampling, filtering, among others)
- Encoding
- Post-processing (filtering, muxing, among others)
Typically, there is a heavy emphasis on the encoding block for visual quality optimizations (Per-Title, 3-Pass, Codec-Configuration, among others).
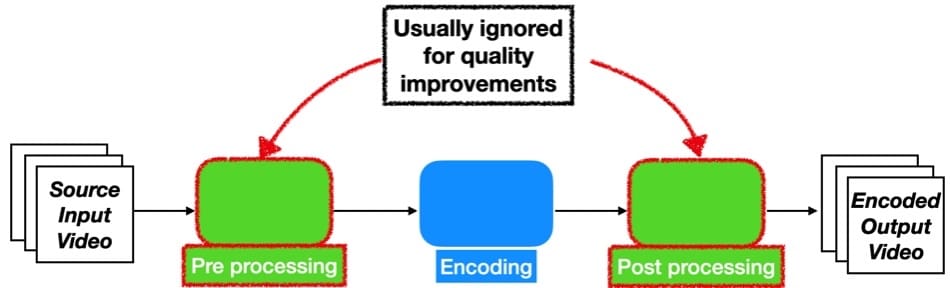
But, the other two (often overlooked) blocks are as important when it comes to visual quality optimization. In this instance, upsampling is a preprocessing step. And by choosing the right upsampling methods, such as super-resolution, one can improve the visual quality of the entire workflow. Sometimes, significantly more than that could be provided from the other blocks.
In the Part-3 of this series, we will delve more deeply into this. We will quantify how much quality improvements one could expect from tuning the pre-processing block with super-resolution. And use some real-life examples.
Synergies with other blocks
(This specific section is primarily meant for advanced readers who understand what Per-Title, VMAF, convex-hull means. Please feel free to skip this section).
Like explained earlier, there are broadly three blocks in a video workflow. Roughly speaking, they work independently. But if we are smart about the design, we can extract synergies and use that to improve the overall video pipelines, that otherwise would not have existed.
One illustrative example is how Per-Title can work in conjunction with the Super-Resolution. This idea is depicted in the following figure.
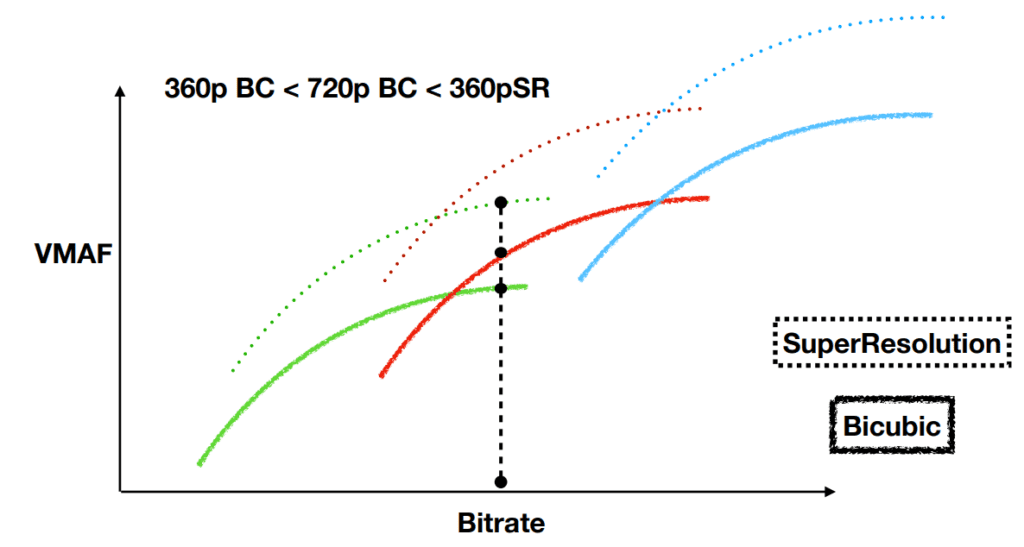
Green => 360p, Red => 720p, Blue => 1080p.
BC : Bicubic, SR : SuperResolution.
The solid line represents the convex hull when the traditional bicubic upsampling method is used, whereas the dotted line represents the convex hull with the super-resolution method (as explained in the last section visual quality is improved by using Super-Resolution).
In the above figure, for the illustrated bitrate: When using the traditional method the choice is clear. We will pick the 720p rendition. But, when using Super-Resolution, the choice is not very clear. We could either pick
- 720p Super-Resolution rendition, or
- 360p Super-Resolution rendition, or
- 720p Bicubic rendition.
The choice is determined by the complexity (vs) quality tradeoff that we are willing to make.
The takeaway message is two blocks synergistically working together to give more options and flexibility for the Per-Title algorithm to work with. Overall, a higher number of options translate to better overall results.
This is just one illustrative example, but within your own video workflows, you could identify regions where super-resolution can work synergically and improve the overall performance.
Targeted Upsampling
If your entire video catalog is a specific kind of content (anime for example), and you want to do a targeted upsample of these contents, then without doubt ML Super-Resolution is the way to go!
In fact, that is what many companies already do. This specific trend will only accelerate in the future, especially considering the popularity of consumer 4K TVs.
Visual quality enhancements, Synergies, and Targeted upsampling are some ideas on how you can incorporate Super-Resolution into your video workflows.

Summary
We continued the story from Part 1. We learned that :
- The convergence of three factors has led to a resurgence in Machine learning-based Super-Resolution.
- The superior performance of Super-Resolution boils down to the fact that it understands the content it is upsampling.
- Super-Resolution can be incorporated into your video workflow in several ways, and consequently, help you increase the end-user experience.
Did you enjoy this post?
Check out part one of the super-resolution series: Super-Resolution with Machine Learning P1
Check out part three: Practical Super-Resolution Deployments and Ensuing Results


