Introduction
Bitmovin was born from research performed by our co-founders at Alpen-Adria-Universität Klagenfurt (AAU) and many of the innovations powering our products today are the direct result of the ongoing ATHENA project collaboration between Bitmovin engineers and the Christian Doppler Laboratory at AAU. This post takes a closer look at our recent combined efforts researching the application of real-time quality and efficiency optimizations to live encoding workflows.
Taking Per-Title Encoding Beyond VOD Workflows
Per-Title encoding is a video encoding technique that involves analyzing and customizing the encoding settings for each individual video, based on its content and complexity. Per-Title Encoding delivers the best possible video quality while minimizing the data required when compared to traditional approaches. This allows content providers to save on bandwidth and storage costs, without impacting the viewing experience.
Bitmovin’s co-founders have been presenting research on the topic since 2011 and Netflix first used the term ‘Per-Title Encoding’ in 2015, so while it’s not a new concept, until now its benefits have been mostly limited to Video-on-Demand workflows. This is largely because of the increased latency added by the complexity analysis stage, something ATHENA began to address with the open-source Video Complexity Analyzer (VCA) project last year.
Without the ability to optimize settings in real-time, live encoding workflows have to use a fixed adaptive bitrate ladder for the duration of the stream and providers are left with a choice: Either set the average bitrate you think you’ll need, knowing that periods of high motion are going to end up looking blocky and pixelated OR set the bitrate high enough to handle the peaks, knowing you’re going to be wasting data when there is less motion and visual complexity in the stream. That is, until now…
Per-Title Live Encoding: Bitmovin + ATHENA collaboration
In addition to the VCA project, ATHENA has been researching its potential applications to live streaming, something Hadi Amirpour presented at the 2022 Demuxed conference, in his talk “Live is Life: Per-Title Encoding for Live Video Workflows” which you can watch at this link.
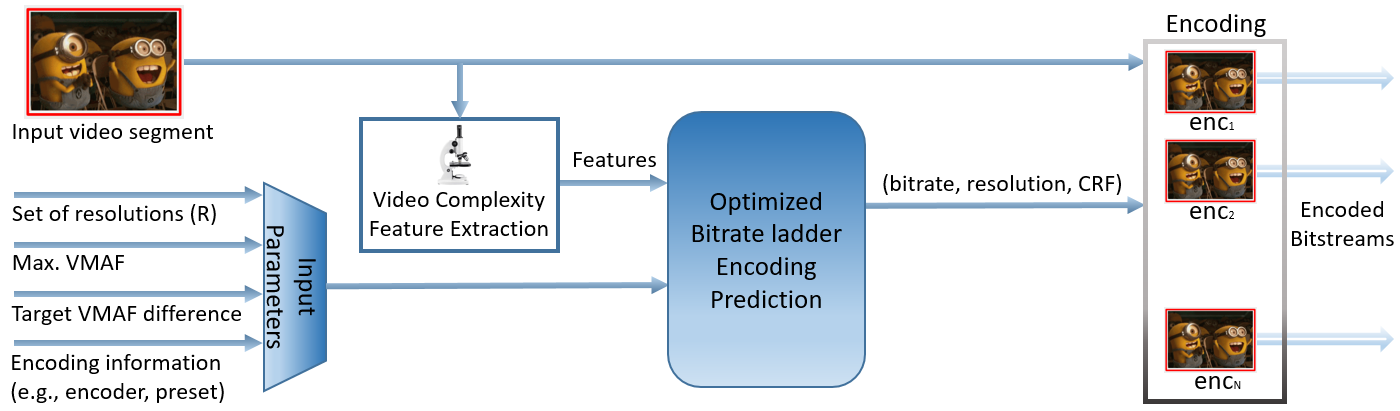
The initial results from the research were promising enough to move into the experimental phase, involving collaboration between ATHENA and Bitmovin’s engineering team to measure the performance and viability of Live Variable Bitrate (VBR) techniques in real-world applications. The proposed approach would involve combining input parameters with real-time extraction of features and complexity in the source video to create a variable, perceptually-aware optimized bitrate ladder. Presented below is a summary of the methodology and results prepared by lead author Vignesh V Menon.
Perceptually-Aware Bitrate Ladder
One of the common inefficiencies when using a fixed bitrate ladder is that you often end up with renditions that, to the human eye, have equivalent visual quality. That means some of them will be redundant and ultimately wasting storage space without improving QoE for the viewer. In a perfect world, each ladder rung would provide a perceivable quality improvement over the previous, up to the maximum point our eyes can detect any difference, denoted as Just-Noticeable-Difference (JND). By setting a maximum VMAF quality score and target VMAF score difference between renditions you can create an ideal theoretical bitrate ladder for the best QoE.
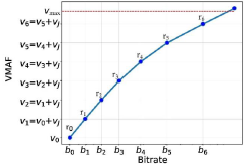
The ideal Live VBR bitrate ladder targeted in this paper. The blue line denotes the corresponding rate-distortion (RD) curve, while the red dotted line indicates VMAF = 𝑣𝑚𝑎𝑥. When the VMAF value is greater than 𝑣𝑚𝑎𝑥, the video stream is deemed to be perceptually lossless. 𝑣𝐽 represents the target VMAF difference.
For this project, we experimented with the following input parameters:
- Set of predefined resolutions
- Minimum and maximum target bitrates
- Target VMAF difference between renditions
- Maximum VMAF of the highest quality rendition
These parameters were then combined with the extracted complexity information to predict and adjust the bitrates necessary to hit the VMAF quality targets. First, based on the pre-configured minimum bitrate, we predict the VMAF score of the lowest quality rung. Next, we use the configured target VMAF difference to determine the VMAF scores of the remaining renditions (up to the max VMAF) and predict the corresponding bitrate-resolution pairs to encode. We also predict the optimal Constant Rate Factor(CRF) for each of these pairs to ensure maximum compression efficiency given our target bitrate. This further reduces file sizes while delivering higher visual quality compared to our reference HLS bitrate ladder CBR encoding using the x264 AVC encoder.
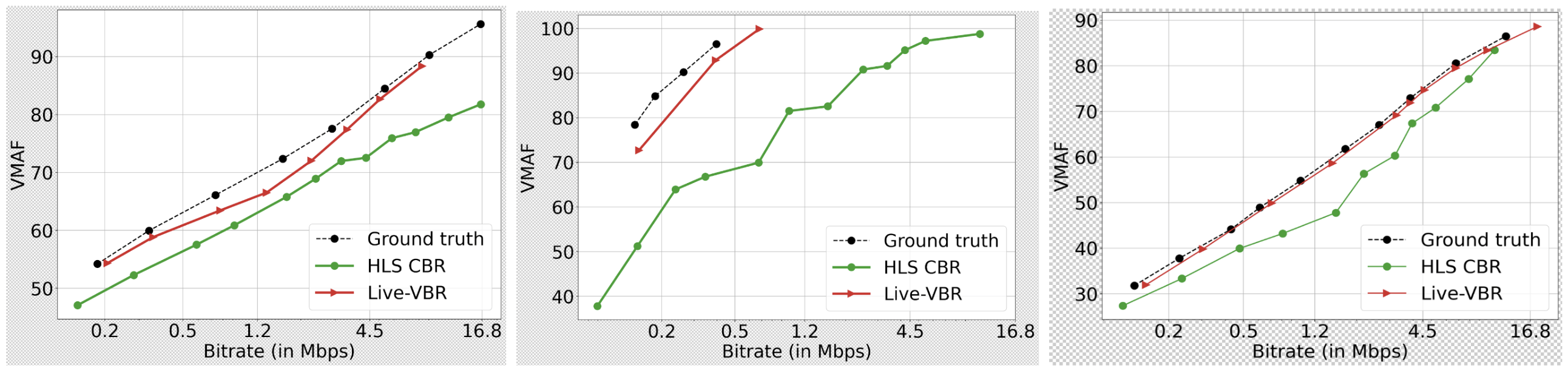
Results
The initial results of our Live VBR Per-Title Encoding have been extremely promising, achieving average bitrate savings of between 7.21% and 13.03% while maintaining the same PSNR and VMAF, respectively, compared to the reference HLS bitrate ladder CBR encoding. Even more impressive is that it delivered those improvements without introducing noticeable latency to the streams, thanks to the real-time complexity analysis from ATHENA’s VCA. Furthermore, by eliminating redundant renditions, we’ve seen a 52.59% cumulative decrease in storage space and a 28.78% cumulative decrease in energy consumption*, considering a JND of six VMAF points.
*Energy consumption was estimated using codecarbon on a dual-processor server with Intel Xeon Gold 5218R (80 cores, frequency at 2.10 GHz). The renditions were encoded concurrently to measure the encoding time and energy.


