

The heterogeneity of the devices on the Internet and the difference among the network conditions of the users make designing a video delivery tool that can adapt to all these differences while maximizing the quality of experience (QoE) for each user a tricky problem. HTTP Adaptive Streaming (HAS) is the de-facto solution for video delivery over the Internet. In HAS, multiple representations are stored for each video, with each representation having a different quality level and/or resolution. This way, HAS streaming sessions can alternate between different quality options based on the network and viewing conditions while delivering the content. However, the requirement to store multiple representations for a single video in HAS brings additional encoding challenges since the source video needs to be encoded efficiently at multiple bitrates and resolutions. Multi-Rate encoding aims to tackle this problem.
This blog post introduces our new approach to multi-rate encoding, called FaRes-ML, Fast Multi-Resolution and Multi-Rate Encoding for HTTP Adaptive Streaming Using Machine Learning (FaRes-ML). But first…
What is Multi-Rate Encoding?
In multi-rate encoding, a single source video needs to be encoded at multiple bitrates and resolutions in order to provide a suitable representation for a variety of network and viewing conditions. The quality level of the encoded video is controlled by the quantization parameter (QP) in the encoder. An example multi-rate encoding scheme is given in Fig.1.

This is a computationally expensive process due to the high data size of videos and the high complexity of video codecs. However, since all of these representations consist of the same content, there is a nice amount of redundancy. Multi-rate encoding approaches exploit this redundancy to speed up the encoding process.
In multi-rate encoding, a representation is chosen as the reference representation (usually the highest [1] or the lowest quality [2] representation), and its information is used to speed up the remaining dependent representations. Since block partitioning is one of the most time-consuming processes in the encoding pipeline, a majority of the multi-rate encoding approach focuses on speeding up this portion of the process.
In block partitioning, each frame is divided into smaller pieces called blocks to achieve more precise motion compensation. Smaller block sizes are used for motion intense areas while larger block sizes are used for stationary areas.
High-Efficiency Video Coding (HEVC) standard uses a Coding Tree Unit (CTU) for block partitioning. By default, each CTU covers a 64×64 pixels-sized square region and each CTU can be divided recursively up to three times with the smallest block size being 8×8 pixels. Each split operation increases the depth level by 1 (i.e. depth 0 for 64×64 pixels and depth 3 for 8×8 pixels). An example of block partitioning for a frame is illustrated in Fig.2.

Introducing the FaRes-ML
FaRes-ML uses Convolutional Neural Networks (CNNs) to predict the CTU split decision for the dependent representations. The highest quality representation from the lowest resolution is chosen as the reference representation. The reference representation is selected from the lowest resolution to speed up the parallel encoding performance since, in parallel encoding, the highest complexity representation bounds the overall encoding time. Thus choosing the reference from a low resolution can increase the parallel encoding performance.
The encoding process in FaRes-ML consists of three main steps:
- The reference representation is encoded with the HEVC reference encoder. Then, the encoding information obtained is stored to be used while encoding the dependent representations.
- Once the encoding information is obtained, the pixel values from the source video in corresponding resolution and the encoding information from the reference representation are fed into the CNN for the given quality level and resolution.
- The output from the CNN is the split decision for the given depth level. This decision is used to speed up the encoding of the dependent representation.
The overall encoding scheme of FaRes-ML is given in Fig.3.

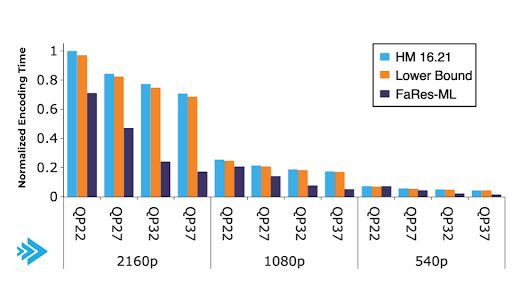
To measure the encoding performance of the FaRes-ML approach, we compared the results to the HEVC reference software (HM 16.21) and the lower bound approach [3]. FaRes-ML achieves 27.71 % time saving for the parallel encoding and 46.27% for the overall encoding while maintaining a minimal bitrate increase (2.05 %). The resulting normalized encoding time graph is given in Fig.4.
Conclusion
As the quality of content resolution improves to new heights with 4K+ resolutions becoming the norm, organizations and researchers are finding new ways to improve the back-end delivery technologies to match the content to its respective device. One of the latest approaches to improving the speed of encoding is the FaRes-ML method, a machine learning-based approach that handles multiple representations in different qualities and resolutions. By applying CNNs to exploit the redundant information in the multi-rate encoding pipeline, FaRes-ML is capable of speeding up overall encodings by nearly 50% in ATHENA’s early-stage experiments with additional improvement parallel encoding methods, all while maintaining a minimal bitrate increase.
Although the FaRes-ML method has been proven in lab environments for single and parallel encodes, its potential can be extended to cover even more encoding decisions (e.g., reference frame selection) to further improve the encoding performance in the near future. Furthermore, the extension of the proposed method for recent video codecs such as Versatile Video Coding (VVC) can be interesting due to the increased encoding complexity of recent video encoding standards, which would significantly decrease the amount of time organizations that operate a back-end workflow could implement the brand new codec.
The team at ATHENA will work closely with Bitmovin in the coming months to determine how FaRes-ML works in real-world applications. If you’re interested in learning more about the Fast Multi-Resolution and Multi-Rate Encoding approach, you can find the full study published in the IEEE Open Journal of Signal Processing journal as an open-access article. More information about the full study can be found in the following links:
If you liked this article, check out some of our other great ATHENA content at the following links:
- Scalable Light Field Coding – Improving the Quality of Experience (QoE) | Bitmovin x ATHENA Labs
- Replacing the Multicast Live Video Streaming Approach with OSCAR | Bitmovin x ATHENA Labs
Sources
[1] D. Schroeder, A. Ilangovan, M. Reisslein, and E. Steinbach, “Efficient multi-rate video encoding for HEVC-based adaptive HTTP streaming,” IEEE Trans. Circuits Syst. Video Technol., vol. 28, no. 1, pp. 143–157, Jan. 2018.
[2] K. Goswami et al., “Adaptive multi-resolution encoding for ABR streaming,” in Proc. 25th IEEE Int. Conf. Image Process., 2018, pp. 1008–1012.
[3] H. Amirpour, E. Çetinkaya, C. Timmerer, and M. Ghanbari, “Fast multi-rate encoding for adaptive HTTP streaming,” in Proc. Data Compression Conf., 2020, pp. 358–358..


