

TL;DR
- Standard distributed encoding splits video into uniform time-based chunks for parallel processing, but scene transitions, motion changes, and shot boundaries rarely align with those fixed cuts, which affects encoding efficiency and quality consistency.
- Bitmovin’s hackathon prototype, Smart Per-Shot Encoding, tested whether segmentation boundaries could be made content-aware by using scene detection to guide keyframe placement within the existing chunk-based processing model, with no changes to encoder internals.
- The setup kept a 4-second target segment duration but allowed boundaries to flex around detected shot transitions, constrained between 1s (minimum) and 7s (maximum) to prevent fragmentation or unpredictable delivery behavior.
- Results were modest but meaningful: ~0.2% average VMAF improvement, ~1% gains at lower quality percentiles (P1/P5), and 2-3% bitrate reduction in CRF-based encodings, all without touching encoder configuration or codec behavior.
Table of Contents
As distributed encoding workflows scale, development teams must increasingly reason about quality and efficiency within system-defined segmentation models. Parallel processing strategies make large-scale VOD encoding predictable and performant, but they also introduce boundaries that do not always reflect how visual content evolves. Scene transitions, motion changes, and visual similarity often occur independently of fixed temporal segmentation, shaping how encoding decisions are applied in practice.
This behavior led us to explore, during a recent hackathon, whether segmentation could become more responsive to content structure without disrupting distributed encoding workflows. As part of this exploration, we experimented with combining shot-aware encoding ideas with existing chunk-based processing approaches.
In this blog, we discuss Smart Per-Shot Encoding, a hackathon prototype focused on segmentation strategies within distributed encoding pipelines, including how it works and what we learned from building it.
Why segmentation becomes difficult to reason about at scale
In distributed encoding systems, segmentation defines how workloads are partitioned and how encoding decisions are applied across parallel processing stages. While this model enables predictable scaling, it can also influence how encoding decisions interact with structural changes in content.

Traditional chunk-based segmentation used in distributed encoding workflows
In practice, segmentation behavior can introduce challenges such as:
- Scene transitions processed across internal chunk boundaries rather than within consistent visual context
- Keyframe placement constrained by execution segmentation rather than content structure
- Rate control behavior influenced by partitioning artifacts
- Bitrate efficiency varying depending on how visual similarity is distributed across processing units
At the same time, segmentation logic is primarily designed to optimize execution characteristics such as throughput and worker utilization. This can make it difficult to isolate how content structure influences encoding outcomes during optimization.

Smart Chunking model enabling flexible output segmentation while maintaining distributed encoding efficiency
What we set out to experiment with in the hackathon
To explore how segmentation behavior influences encoding outcomes, this hackathon experiment focused on combining shot-aware encoding concepts with Bitmovin’s existing chunk-based processing model. Rather than modifying encoder internals, the objective was to evaluate whether internal boundary placement could better reflect visual continuity while preserving distributed execution characteristics.
The prototype introduced a workflow in which scene detection guided keyframe placement within larger internal processing chunks. This enabled encoded segments to align more closely with shot transitions while still operating within the constraints of parallelized encoding execution.
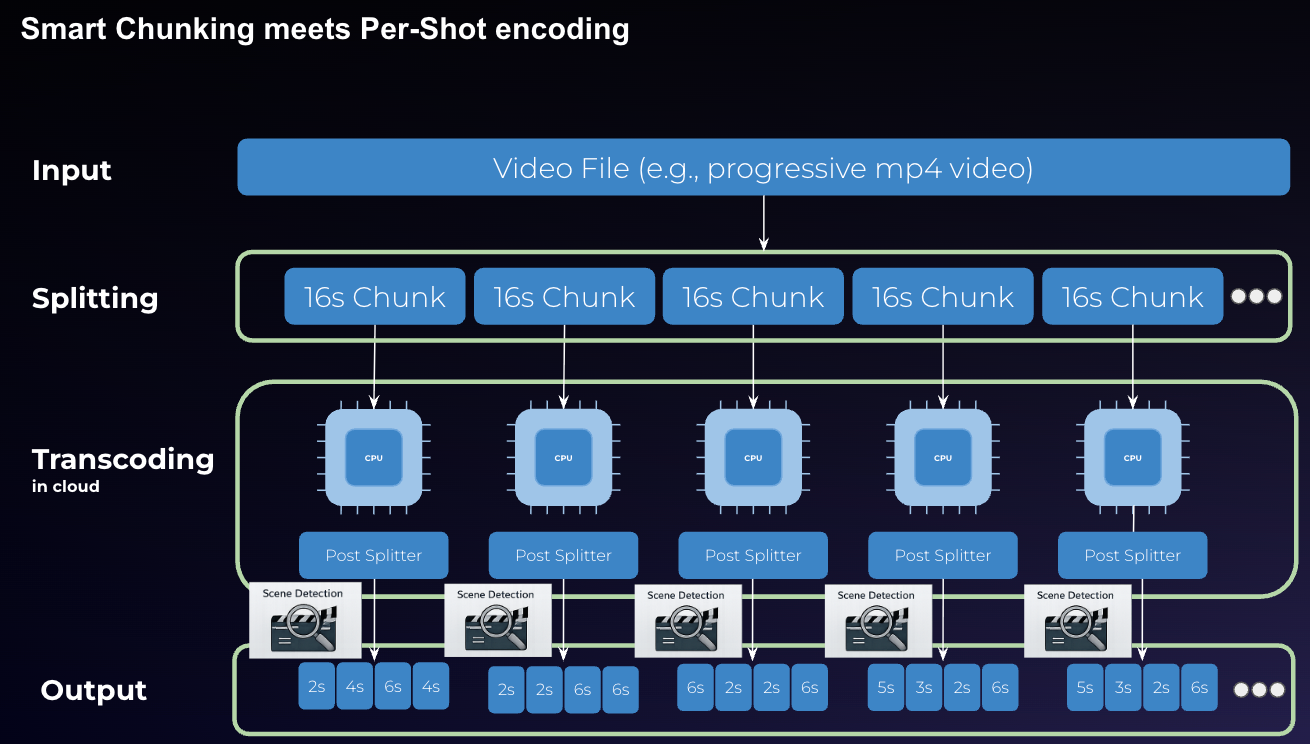
Per-shot boundary alignment within Smart Chunking execution model
Key aspects of the experimental approach included:
- Using larger internal processing chunks while allowing flexible output segmentation
- Applying scene detection prior to encoding to influence boundary placement
- Generating custom keyframe positions to simulate shot-aware encoding behavior
- Evaluating how these adjustments affected bitrate efficiency and quality consistency
This setup allowed segmentation behavior to be explored without requiring changes to production encoding architecture.
How the prototype was built
The experimental setup compared a fixed-duration segmentation baseline with a shot-aware configuration operating under controlled flexibility. In the baseline workflow, segments were generated using a consistent 4s duration, reflecting a standard execution-driven segmentation model.
In the shot-aware configuration, segmentation retained the same 4s target duration, but allowed boundaries to shift around detected scene transitions. This flexibility was intentionally bounded to prevent excessive fragmentation or disproportionately long segments, ensuring that the comparison reflected segmentation behavior rather than uncontrolled execution variability.
Key characteristics of the shot-aware configuration included:
- 4s target segment duration aligned to scene structure
- Boundary deviation permitted within a constrained tolerance window
- Minimum segment duration of 1s to avoid over-fragmentation
- Maximum segment duration of 7s to preserve delivery predictability
- External scene detection used to guide keyframe placement
Because segmentation flexibility remained constrained, the experiment evaluated boundary sensitivity rather than fully adaptive shot-based encoding.
What the experiment revealed
Aligning segmentation boundaries more closely with shot transitions produced measurable but moderate improvements across tested content. While average quality gains remained limited, more consistent changes were observed in lower percentile quality frames.
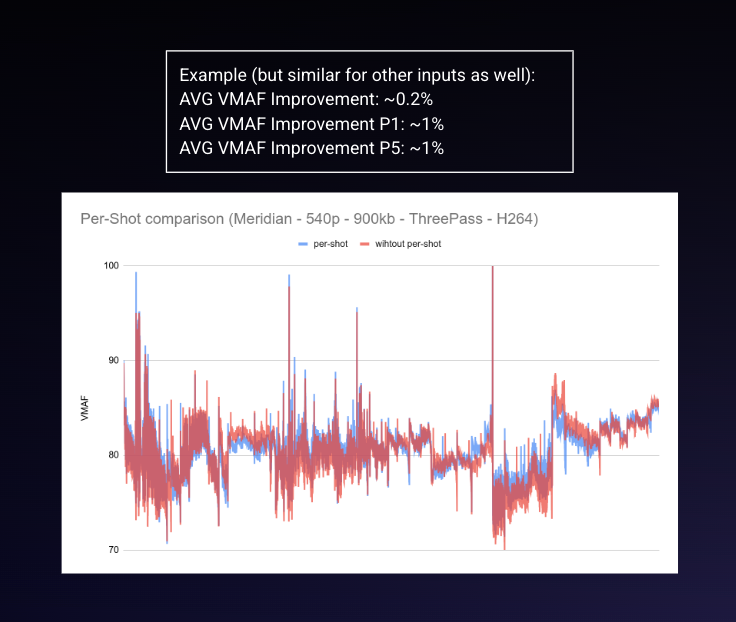
Per-shot vs fixed segmentation VMAF comparison from the example asset
While the observed improvements were modest in magnitude, they are notable because they emerged without modifying encoder configuration or codec behavior. Instead, they reflect how segmentation strategy alone can influence encoding outcomes, suggesting an optimization dimension that is often treated as fixed.
Key observations included:
- Average VMAF improvement of approximately 0.2% across evaluated assets
- Improvements of around 1% in lower percentile measurements such as P1 and P5
- Bitrate reductions of roughly 2–3% in CRF-based encodings while maintaining comparable perceptual quality
- Comparable VMAF outcomes achieved at lower bitrate in shot-aware configurations relative to fixed segmentation baselines
While the observed improvements were modest in magnitude, they are notable because they emerged without modifying encoder configuration or codec behavior. Instead, they indicate that segmentation strategy alone can influence encoding behavior, particularly in ways that are not fully captured by average quality metrics.
What we learned from the project
The project showed that segmentation decisions alone can influence encoding behavior in measurable ways. Adjusting boundary placement affected how rate control and keyframe distribution interacted with content structure, even though encoder configuration remained unchanged. While the resulting quality improvements were modest, their consistency across constrained test conditions suggests that segmentation strategy plays a more active role in encoding outcomes than is often assumed.
At the same time, introducing content-aware segmentation into distributed workflows revealed practical system limitations. Execution models designed for predictability and scalability can restrict how much adaptivity can be expressed without introducing complexity. This highlights segmentation as an underexplored optimization dimension, particularly when evaluated beyond average quality metrics.
FAQs
What is chunk-based segmentation in distributed video encoding?
In distributed encoding systems, video is divided into fixed-duration segments — or “chunks” — so that multiple processing units can encode them in parallel. This makes large-scale VOD encoding predictable and scalable. The trade-off is that these fixed boundaries are determined by execution logic, not by what’s happening visually in the content. Scene transitions, motion changes, and shot cuts often fall in the middle of a chunk rather than at its boundary, which can affect rate control behavior, keyframe placement, and bitrate efficiency.
What is Smart Per-Shot Encoding?
Smart Per-Shot Encoding is a hackathon prototype developed by Bitmovin that explores combining shot-aware segmentation with the existing chunk-based distributed encoding model. Rather than using fixed-duration boundaries for every segment, it uses scene detection to shift boundaries toward shot transitions, so encoded segments more closely reflect the visual structure of the content, while still operating within the constraints of parallelized encoding.


