

In the previous series of posts, we set a baseline of compression knowledge by defining how lossy compression algorithms work for images and breaking down the JPEG image standard. Now that we’ve covered our image compression basics, it’s time to move up to the next level with video -as you might have guessed – a time-ordered sequence of frames. Although compression is incredibly important for image distribution, it’s even more so for video. As seen with compressing images using the JPEG standard, the brute force approach to video compression is MJPEG or Motion-JPEG, where the Huffman encoding is applied and frames are the size of JPEG images from a digital camera. Motion JPEG 2000 is heavily deployed in the industry and used across multiple commercial digital still cameras.
Given that the image compression techniques necessary to efficiently transmit an image are complex, more video compression techniques are available and applied for video. Video compression, otherwise known as video encoding, is the process of converting a raw format into a compressed one (ex: RGB16 or MJPEG to MP4). Encoding is the first step in the compression chain for internet delivery of video. Additional transcodes can be applied to a video, hence taking the output of the encoder and compressing further, creating a better-compressed file for transmission. So, what happens in video compression?
How to Compress Video
The basic idea behind video encoding is to exploit high correlations in successive frames. To do so, predictive coding, otherwise known as Motion Estimation (ME), is applied to the preceding and (occasionally) succeeding frames to remove spatial redundancy by subtracting successive frame differences; Specifically, the first frame is like a full JPEG image, the second frame is the difference over time from the first frame. Therefore coding the residual error or the difference. If the difference is small from the previous image, then a high compression ratio can be achieved.
The second video compression algorithm (after Huffman encoding) is Motion Compensation, where the vectors determined from the ME step are used to describe the picture in terms of the transformation of a reference frame to the frame currently being analyzed (illustrated below). Each image is divided in NxN blocks (where the default for N = 16) and run through an algorithm called Motion Estimation. Break up of a video frame into macroblocks:
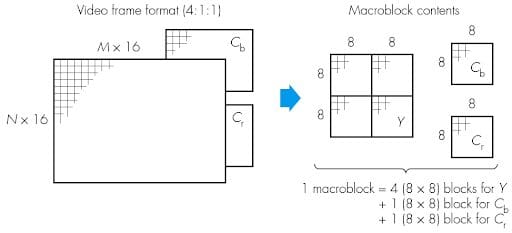
Motion Estimation determines the motion vectors which describe the transformations from one picture to the next. One part of a picture is subtracted from the same part (block) in the previous image. This scan and subtraction process is illustrated below:
Frame-Types in Video Compression
There are three main types of frames, which are grouped together in Groups of Pictures (GOP):
I-frames
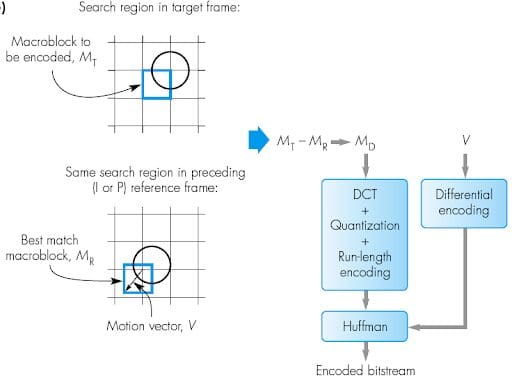
Otherwise known as Independent frames, I-frames don’t need additional frames to be decoded – much like JPEG images. These frames are also the largest in size of the three and appear the least frequently in videos compared to the other frame types. The implementation schematics of I-frames do not need any motion compensation and the encoding process is the same as for the JPEG standard. The graph below illustrates this process:

The contents of the target frame are divided up into different macroblocks and a Forward Discrete Cosine Transform (FDCT) is applied. The FDCT process provides a smoothened out frequency distribution of the macroblocks in terms of pixel variations in a block. Once the pixels in the block have been converted to frequencies, the quantization step is applied to the macroblocks. In this step, the analog signal (frequency) is converted into a vector with different amplitude and size, depending on the spatial redundancy of the block. The less redundancy (more variation) in the block, the greater the size and amplitude described by the quantization vector; thus less compression is applied. Next, entropy encoding converts the amplitude in bits and the size identified in the quantization step and encodes this information in a bitstream – usually starting from the Most Significant Bit. This is called progressive mode and the image can then be decoded with successive approximation, through iterative scans. This is why when you are loading a JPEG image on the internet, it initially looks blocky and more details are added as the image loads. The average size on disk for a 320×240 I-Frame is 14.8KB.
P-frames
Otherwise known as Predictive frames, P-frames are frames that are relative to the preceding P-frame OR preceding I-frame. When Motion Compensation is applied to P frames, the best macroblock (the one with less variance) in the previous frame is used to encode the target macroblock. The graph below illustrates this process:

The implementation schematics of P-frames need Motion Compensation to find the difference between the previous frames, as illustrated below:

In addition to the steps carried out for I-frames, P-frames need few additional steps: I-frames introduce a feedback mechanism where the content of the target frame and all its macroblocks are encoded with reference to previous frames. The reference frame content is compared from the point of view of motion estimation with the current frame. This is done via Direct Quantization(DQ) and the Inverse Discrete Cosine Transform (IDCT). The differences are then encoded in the bitstream. The average size on disk for a (320×240) P-Frame is 6KB.
B-frame
Otherwise known as Bidirectional frames. B-Frames are relative to both preceding and succeeding I or P frames:
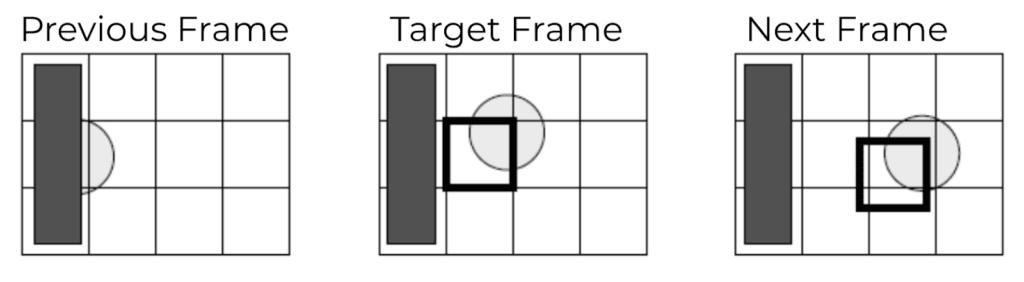
More efficient than looking at full successive pictures, B-frames divide a frame into smaller parts or blocks, like in JPEG coding.
When Motion Compensation is applied to B-frames, an encoder seeks the best reference macroblock for compression based on previous and upcoming frames. The implementation schematics of B-frames need motion compensation to find the best-suited macroblock for the target macroblock by selecting which has the least variation from the target macroblock.

All predictions are calculated using the same method, albeit more complex, as P-Frames. The implementation schematics of B-frames look like:

The B-frames implementation process is similar to the ones for I and P frames, but with the additional step of comparing successive frames. The additional step implies that B-frames will take longer to encode because you need to download and decode the extra data. Although a delay is introduced at the computation step, the result is more efficient encodes and a faster distribution process. The average size on disk for a 320×240 B-Frame is 765B.
Efficient video compressions use a mix of I, P and B frames – this mix approached is illustrated within a bitstream here:

This process is even more efficient when searching for just the right parts of the image to subtract from the previous frame.
Step-by-Step Video Compression Process Summarized
To recap:
- A video is a sequence of frames
- Each frame is split up into NxN macroblocks
- For each NxN macroblock DCT is applied (measuring brightness changes in a block)
- Quantization is applied on the resulting frequencies and then discretized
- Frames are encoded based on the differences identified during Motion Estimation
- There are 3 types of frames in video compression and video encoding:
- I-Frame: Independent frames, like a full JPEG image, are coded fully and individually – without referencing any other frames. About 15Kb for an I-frame of 320×240.
- P-Frame: Preceding frames are frames that only measure the differences from previous frames. About 6Kb for an P-frame of 320×240.
- B-Frame: Bidirectional frames are encoded based on the differences between the preceding and successive frames. About 750B for a B-Frame of 320×240.



