


As with most technical products, documentation is a critical factor to customer success, that sentiment is made even more true for API driven products, but good documentation is only part of the story. Sure we provide a beautiful dashboard, where it is definitely possible to start an encoding, but we still find that the bulk of encodings processed in our system are started via API calls. Even then, the best API documentation will only get you so far – without an API SDK, you would need to implement all the calls yourself before you would be able to enjoy your first encoded content. That’s why the Bitmovin team always provides detailed documentation in several different programming languages for each API SDK, so any developer can jump-start their first encode in a matter of minutes.
It’s no trivial endeavor to keep documentation and SDKs in sync, especially when new features are added on a weekly basis. We needed a better way to connect the parts, and our search led us to the OpenAPI 3.0 specification.
Long story short: over the course of the last year, we migrated our existing API Blueprint documentation to the OpenAPI format. This migration details more than 800 endpoints, so a considerable amount of work was necessary, but because of it we are not only able to provide stunning and detailed documentation, we can also generate our API SDKs, so they stay in sync with our full feature set.
Let’s jump into the details of our journey and showcase the other great things we accomplished along the way.
What is OpenAPI?
The OpenAPI specification, formerly known as Swagger specification, defines how to describe and document RESTful web services in a machine-readable way. For us, this is critical, as we want to provide beautiful and easily discoverable documentation to our customers. Over time different specification formats, like RAML or API Blueprint were invented, but the industry converged more and more toward OpenAPI. In 2015 the OpenAPI Initiative was created, which brought the efforts of various companies like Google, Microsoft, IBM and others under one umbrella. This sent a strong signal to the industry that this documentation format was on its way to becoming the de facto standard and could be used with a high degree of confidence. Since then a lot of great tooling has been contributed by different companies and by the community.
A technical background on OpenAPI
An OpenAPI document is either written in JSON or YAML syntax and is structured into the following blocks:
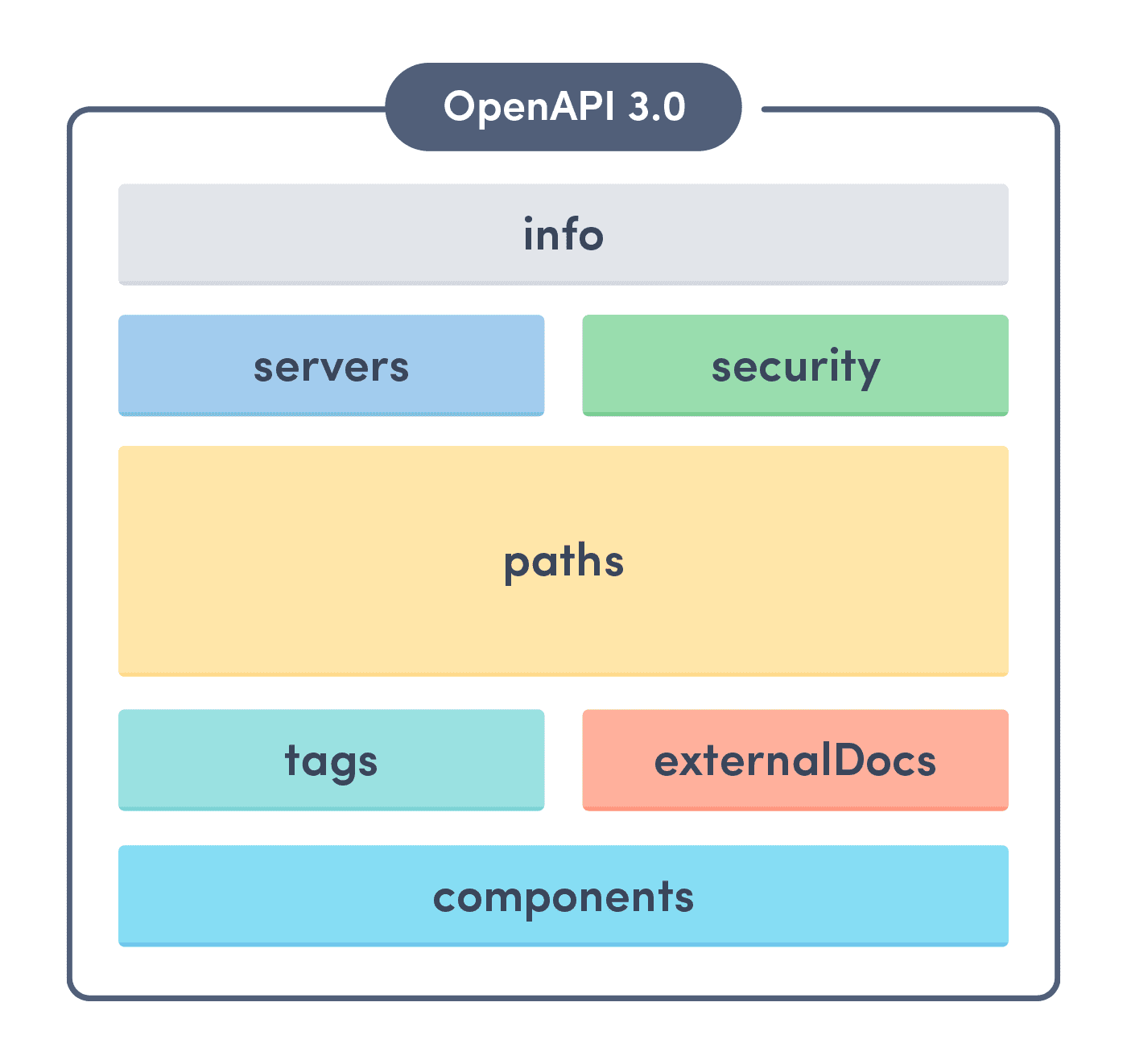
The most important blocks for us are components, which contain all of our models used in HTTP bodies of requests and/or responses, and paths, which contain the list of all endpoints and actions our API provides. A simple example of an OpenAPI document can be found here.
So why migrate to OpenAPI?
Better documentation helps engineering teams scale easily and keep up with demanding projects. Here are some of the main reasons Bitmovin decided to migrate to OpenAPI:
1. Simplified and searchable online documentation
With our new API definition, we were able to explore the documentation-oriented tooling of the OpenAPI ecosystem. This led us to the swagger-ui project which now serves as the basis for our online API reference. Now, our documentation not only lists each endpoint of our products, but it also describes them down to the last detail, including sample requests and sample responses.
We find that most technically minded individuals prefer to learn about new features through testing, that’s why we enable logged in users to send off requests directly from the endpoint documentation. To see how this works, just click on the “Try it out” button and fill in the request details – no need to enter your API key, we already have it configured for you. Don’t have a Bitmovin account? Register today for a free 30 day trial.
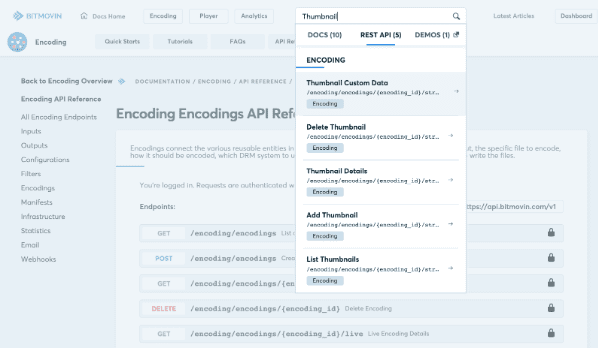
When creating documentation it is not only important to provide meaningful, complete and up-to-date information, it is important that all this can be easily discovered and accessed. That’s why we built a powerful full-text search functionality around our API documentation. For example, want to find which endpoints to use to create thumbnails for your encoding? Just search for “thumbnails” in the top search bar and all the resources are listed within the blink of an eye.
2. Multi-Language SDK Code generation
To make it as easy and fun as possible for our customers to work with our products, we are providing API SDKs in seven different languages: Java, JavaScript, Python, Go, PHP, Ruby and C#. Those SDKs are actively supported, but it was always a challenge for us to keep up with the speed of product development. Every new feature added means that it also had to be implemented in those SDK code bases. As this is a time consuming (and error-prone) process, we decided to explore the possibilities of SDK code generation.
The OpenAPI generator is an open source project written in Java that can generate API SDKs for a number of different languages. This is done via a combination of language specific code and a couple of Mustache templates. The generator code defines which keywords are reserved in a specific language or defines the casing of variables and methods. The templates are basically code snippets with placeholders which, combined together with our API definition, will form the API SDK code needed to communicate with the API.
We evaluated the existing generator and found it great for small to medium-sized APIs, but for our use case, it was ultimately too limiting. Let’s take a look at an example: to get the details for a specific AWS S3 input that was created in the API, this endpoint needs to be called:
GET https://api.bitmovin.com/v1/encoding/inputs/s3/{input_id}
After generating the Java SDK with the default generator we would be able to call this endpoint in the following way:
S3Input s3Input = client.getEncodingInputsS3ByInputId(inputId);
As you can see the method gets generated as part of a client object. In fact, this single client object will contain all of our API methods – our whole API surface.
One key aspect of our philosophy is that our customers need to be able to configure every detail of their encoding jobs. This power and freedom we provide naturally leads to a larger API surface. Instead of having all these methods in one single API client object, we wanted our SDKs to be structured as similar to our API as possible. They should be easily explorable and make it clear to understand which endpoint would be called at any time:
S3Input s3Input = client.encoding.inputs.s3.get(inputId);
Because of this, we decided to write our own generator logic and templates on top of the generator project. Each slash (/) of the endpoints URL should also be a separator in our SDKs, which means that each resource’s methods are generated in their own small sub-API client object. This ensures that the users of our SDKs won’t get overwhelmed by the number of methods they need to choose from at any given time. It enables the exploratory approach of working with our API we aim for.
When we started out writing our own generator code and templates, we estimated that it would be a relatively trivial task – after all, we just wanted to restructure the code that was already being generated. However, it turned out that the current design of the generator was not encouraging extensions the way we planned them. We still managed to use the generator project as a basis and we were grateful to have it, but we had to invest much more time than expected. After all this work, we felt that a dynamically typed language like JavaScript might be a better fit for an API SDK generator, as it provides natural customization possibilities. Another point we might have underestimated was the effort needed to design the API SDKs as idiomatic as possible for their respective language. Using the SDKs should be fun and feel natural for our customers but at the same time the code needed to be future proof, encouraging additions without breaking changes.
3. Continuous Integration and delivery
Now that we were able to generate the API SDKs, the next step was to automate this process. We were now at a point where we could prototype new API endpoints in our documentation and have an auto-generated and tested SDK ready for use within minutes. During this process, the documentation gets also automatically sanity-checked and a slew of semantic validations is executed.
To be 100% sure that every SDK version is fully functional, we created a suite of dozens of stub HTTP calls that each SDK has to issue and validate in integration tests. If an SDK does not execute a request of the suite or fails to process a response correctly, we immediately stop the delivery process and alert our engineers of the problem. We use Wiremock as a mock server as it turned out to be the perfect tool to integrate into our automated build process.
The Impact of Adopting OpenAPI for the Engineering Team
At Bitmovin, the discussions about the design of new endpoints now focus on documentation or generated code. We can even write – not yet functional but compiling – example workflows that show how a new feature will be used in the context of other features. As soon as we are happy with the documentation, we can begin to implement the necessary changes in our backend services. Finally, we are dogfooding our generated SDK by writing end-to-end tests that start (a lot of) real encodings on a nightly basis. All these steps make sure that everything was implemented correctly in the backend services and matches what we defined in our API documentation, a safety we never had before with our old API documentation alone.
What’s New in Bitmovin’s OpenAPI Journey
We already released 6 out of 7 planned API SDKs to the public. We now have two SDKs (Java and JavaScript) available as stable releases, which means they won’t experience breaking changes in the future. The other SDKs will follow in the near future and we are happy to take ideas and suggestions from you, so we can deliver the best SDKs possible. Every SDK will be released with a set of examples, so you can quickly see how the new SDK can be used.
We are really happy we switched to OpenAPI for our API documentation, as this will save us a lot of time in the future, which we can now invest in feature development. The benefits of guaranteed correct and super fast SDK updates, beautiful and searchable online documentation and rich tooling, and more that we haven’t tapped into yet, all add up to a huge improvement in quality for our customers and us. We are eager to see what we can do next with OpenAPI.
OpenAPI specific links:
SDK repositories:
- https://github.com/bitmovin/bitmovin-api-sdk-dotnet
- https://github.com/bitmovin/bitmovin-api-sdk-go
- https://github.com/bitmovin/bitmovin-api-sdk-java
- https://github.com/bitmovin/bitmovin-api-sdk-javascript
- https://github.com/bitmovin/bitmovin-api-sdk-php
- https://github.com/bitmovin/bitmovin-api-sdk-python
Video technology guides and articles
- Back to Basics: Guide to the HTML5 Video Tag
- What is a VoD Platform?A comprehensive guide to Video on Demand (VOD)
- Video Technology [2022]: Top 5 video technology trends
- HEVC vs VP9: Modern codecs comparison
- What is the AV1 Codec?
- Video Compression: Encoding Definition and Adaptive Bitrate
- What is adaptive bitrate streaming
- MP4 vs MKV: Battle of the Video Formats
- AVOD vs SVOD; the “fall” of SVOD and Rise of AVOD & TVOD (Video Tech Trends)
- MPEG-DASH (Dynamic Adaptive Streaming over HTTP)
- Container Formats: The 4 most common container formats and why they matter to you.
- Quality of Experience (QoE) in Video Technology [2022 Guide]


