

This blog post is the final piece of our Live Low-Latency Streaming series, where we previously covered the basic principles of low-latency streaming in OTT and LL-DASH. This final post focuses on latency when using Apple’s HTTP Live Streaming (HLS) protocol and how the latency time can be reduced. This article assumes that you are already familiar with the basics of HLS and its manifest/playlist mechanics. You can view the first two posts below:
Why is latency high in HLS?
HLS in its current specifications favors stream reliability over latency. Higher latency is accepted in exchange for stable playback without interruptions. In section 6.3.3. Playing the Media Playlist File the HLS specification states that a playback client
SHOULD NOT choose a segment that starts less than three target durations from the end of the playlist file
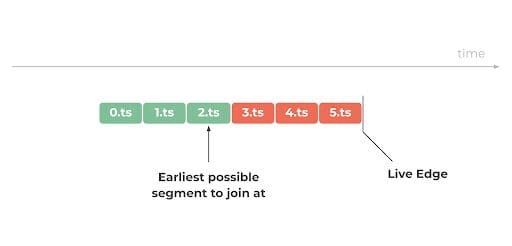
Honoring this requirement results in having a latency of at least 3 target durations. Given typical target durations for current HLS deployments of 10 or 6 seconds, we would end up with a latency of at least 30 or 18 seconds, which is far from low. Even if we choose to ignore the above requirement, the fact that segments are typically produced, transferred, and consumed in their entirety poses a high risk of buffer underruns and subsequent playback interruptions, as described in more detail in the first part of this blog series.
The HLS media playlist for the above depicted this live stream would look something like this:
[bg_collapse view=”button-blue” color=”#f7f7f7″ icon=”eye” expand_text=”View HLS media playlist” collapse_text=”Close HLS media playlist” ]
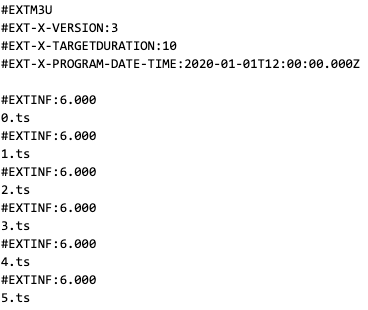
[/bg_collapse]
Road to Low-Latency HLS
2017’s Periscope, the most popular platform for live streaming of user-generated content at the time, investigated streaming solutions to replace their RTMP- and HLS-based hybrid approach with a more scalable one. The requirement was to offer similar end-to-end latency as RTMP but in a more cost-effective way; considering that their use case was streaming to large audiences. Periscope presented their solution to high latency issues: which took Apple’s HLS protocol, made two fundamental changes and called it Low-Latency HLS (LHLS):
- Segments are delivered using HTTP/1.1 Chunked Transfer Coding
- Segments are advertised in the HLS playlist before the are available
If you read our previous blog posts about Low-Latency streaming, you might recognize these simple concepts as being the key ingredients for today’s OTT-based Low-Latency streaming approaches, like LL-DASH. Periscope’s work likely sparked and influenced the following developments around low-latency streaming such as LL-DASH and a community-driven initiative for defining modifications to HLS aiming to reduce streaming latency that started at the end of 2018.
The core of the community proposal for LHLS was the same as the aforementioned concepts. Segments should be loaded in chunks using HTTP CTE and early availability of incomplete segments should be signaled using a new #EXT-X-PREFETCH tag in the playlist. In the example below, the client can already load and consume the currently available data of 6.ts and continue to do so as the chunks become available over time. Furthermore, the request for the segment 7.ts can be made early on to save network round-trip time, even though production had not started yet. It is also worth mentioning that the LHLS proposal preserves full backward-compatibility allowing standard HLS clients to consume such streams. This was the gist of the proposed implementation; you can find the full proposal in the hlsjs-rfcs GitHub repository.
[bg_collapse view=”button-blue” color=”#f7f7f7″ icon=”eye” expand_text=”View LHLS media playlist proposal” collapse_text=”Close LHLS media playlist proposal” ]

[/bg_collapse]
Individuals across several companies in the media industry came together to work on this proposal with the hope that also Apple, being the driving force behind HLS, would join in and work the proposal into the official HLS specification. However, things came to fruition very differently than expected as Apple presented its own preliminary version, a very different approach during their 2019’s Worldwide Developers Conference.
Despite it being (and staying) a proprietary approach, some companies, like Twitch, are successfully using it in their production systems.
Apple’s Low-Latency HLS
In this section we’ll cover the principles of Apple’s preliminary specification for Low-Latency HLS.
Generation of Partial Media Segments
While HLS content is split into individual segments, in low-latency HLS each segment further consists of parts that are independently addressable by the client. For example, a segment of 6 seconds can consist of 30 parts of 200ms duration each. Depending on the container format, such parts can represent CMAF chunks or a sequence of TS packets. This partitioning of segments decouples the end-to-end latency from the long segment duration and allows the client to load parts of a segment as soon as they become available. Compared to LL-DASH, this is achieved by using HTTP CTE, however, the MPD does not advertise individual parts/chunks of segments.
[bg_collapse view=”button-blue” color=”#f7f7f7″ icon=”eye” expand_text=”View partial media segment generation in low latency HLS” collapse_text=”Close partial media segment generation in low latency HLS” ]
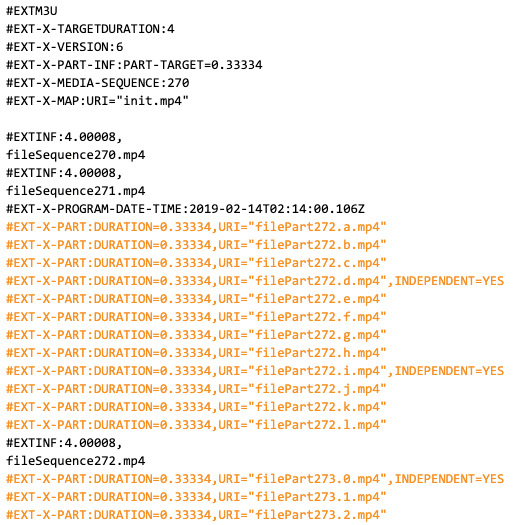
[/bg_collapse]
Partial segments are advertised using a new EXT-X-PART tag. Note that partial segments are only advertised for the most recent segments in the playlist. Furthermore, the partial segments (filePart272.x.mp4) and the respective full segments (fileSequence272.mp4) are offered.
Partial segments can also reference the same file but at different byte ranges. Clients can thereby load multiple partial segments with a single request and save round-trips compared to making separate requests for each part (as seen below).

Preload hints and blocking of Media downloads
Soon to be available partial segments are advertised prior to their actual availability in the playlist by a new EXT-X-PRELOAD-HINT tag. This enables clients to open a request early and the server will respond once the data becomes available. This way the client can “save” the round-trip time for the request.

Playlist Delta Updates
Clients have to refresh HLS playlists more frequently for low-latency HLS. Playlist Delta Updates can be used to reduce the amount of data transferred for each playlist request. A new EXT-X-SKIP tag replaces the content of the playlist that the client already received with a previous request.
Blocking of Playlist reload
The discovery of new segments becoming available for an HLS live stream is usually applied by the client reloading the playlist file in regular intervals and checking for new segments being appended. In the case of low-latency streaming, it is desirable to avoid any delay from a (partial) segment becoming available in the playlist to the client discovering its availability. With the playlist reloading approach, such discovery delay can be as high as the reload time interval in the worst case.
With the new feature of blocking playlist reloads, clients can specify which future segment’s availability they are awaiting and the server will have to hold onto that playlist request until that specific segment becomes available in the playlist. The segment to be awaited for is specified using a query parameter on the playlist request.
Rendition Reports
When playing at low latencies, fast bitrate adaptation is crucial to avoid playback interruptions due to buffer underruns. To save round-trips during playlist switching, playlists must contain rendition reports via a new EXT-X-RENDITION-REPORT tag that informs about the most recent segment and part in the respective rendition.
![]()
Conclusion
For more detailed information on Apple’s low-latency HLS take a look at the Preliminary Specification and the latest IEFT draft containing low-latency extensions for HLS.
We can conclusively say that low-latency HLS increases complexity quite significantly compared to standard HLS. The server will have its responsibilities expanded, from simply serving segments to supporting several additional mechanisms that clients use to save network round-trips and speed up segment delivery which ultimately enables lower end-to-end latency. Considering that the specification remains subject to change and is yet to be finalized, it might still take a while until streaming vendors pick it up and we finally see low-latency HLS in the wild. In short, live low latency streaming using HLS is possible, but at a large cost to server complexity, there are measures being developed to reduce complexity and server load, but it’ll take wider spread adoption by major stream providers for this to happen.


